第22回.CSV読み書き(csvモジュール)

Pythonの標準ライブラリのcsvモジュールを使いCSVファイルを読み書きします。
前回の続きとしてcsvの書き込みをやります。
csvモジュールのより詳細な解説をします。
そして、フォルダ内の複数csvを一つにまとめたcsvを出力するスクリプ作成へと進みます。
目次
csvモジュールの仕様
"このデータを Excel で推奨されている形式で書いてください"とか
"データを Excel で作成されたこのファイルから読み出してください" と言うことができます。
プログラマはまた、他のアプリケーションが解釈できる CSV形式を記述したり、独自の特殊な目的をもったCSV形式を定義することができます。
リンクは公式ドキュメントにリンクしています。
csvモジュールの関数
| 関数 | 説明 |
| reader | csv.reader(csvfile,dialect='excel',**fmtparams) 与えられたcsvfile内の行を反復処理するような reader オブジェクトを返します。 |
| writer | csv.writer(csvfile,dialect='excel',**fmtparams) ユーザが与えたデータをデリミタで区切られた文字列に変換し、与えられたファイルオブジェクトに書き込むための writer オブジェクトを返します。 |
| register_dialect | csv.register_dialect(name[,dialect[,**fmtparams]]) dialectをnameと関連付けます。 |
| unregister_dialect | csv.unregister_dialect(name) nameに関連づけられた表現形式を表現形式レジストリから削除します。 |
| get_dialect | csv.get_dialect(name) nameに関連づけられた表現形式を返します。 |
| list_dialects | csv.list_dialects() 登録されている全ての表現形式を返します。 |
| field_size_limit | csv.field_size_limit([new_limit]) パーサが許容する現在の最大フィールドサイズを返します。 |
csvモジュールのクラス
| クラス | 説明 |
| DictReader | class csv.DictReader(f,fieldnames=None,restkey=None,restval=None,dialect='excel',*args,**kwds) 通常のリーダーのように動作するオブジェクトを作成しますが、各行の情報をdictにマッピングします。 |
| DictWriter | class csv.DictWriter(f,fieldnames,restval='',extrasaction='raise',dialect='excel',*args,**kwds) 通常の writer のように動作しますが、辞書を出力行にマップするオブジェクトを生成します。 |
| Dialect | class csv.Dialect Dialectクラスはコンテナクラスで、基本的な用途としては、その属性を特定のreaderやwriterインスタンスのパラメータを定義するために用います。 |
| excel | class csv.excel excelクラスは Excel で生成される CSV ファイルの通常のプロパティを定義します。 これは 'excel' という名前の dialect として登録されています。 |
| excel_tab | class csv.excel_tab excel_tabクラスは Excel で生成されるタブ分割ファイルの通常のプロパティを定義します。 これは 'excel-tab' という名前の dialect として登録されています。 |
| unix_dialect | class csv.unix_dialect unix_dialectクラスは UNIX システムで生成される CSV ファイルの通常のプロパティ (行終端記号として'\n'を用い全てのフィールドをクォートするもの) を定義します。 これは 'unix' という名前の dialect として登録されています。 |
| Sniffer | class csv.Sniffer Snifferクラスは CSV ファイルの書式を推理するために用いられるクラスです。 |
csvモジュールの定数
| 定数 | 説明 |
| csv.QUOTE_ALL | writerオブジェクトに対し、全てのフィールドをクオートするように指示します。 |
| csv.QUOTE_MINIMAL | writerオブジェクトに対し、delimiter、quotecharまたはlineterminatorに含まれる任意の文字のような特別な文字を含むフィールドだけをクオートするように指示します。 |
| csv.QUOTE_NONNUMERIC | writerオブジェクトに対し、全ての非数値フィールドをクオートするように指示します。 |
| csv.QUOTE_NONE | writerオブジェクトに対し、フィールドを決してクオートしないように指示します。 |
| Dialectの属性 | 説明 |
| delimiter | フィールド間を分割するのに用いられる 1 文字からなる文字列です。 デフォルトでは','です。 |
| doublequote | フィールド内に現れたquotecharのインスタンスで、クオートではないその文字自身でなければならない文字をどのようにクオートするかを制御します。 Trueの場合、この文字は二重化されます。 Falseの場合、escapecharはquotecharの前に置かれます。 デフォルトではTrueです。 |
| escapechar | writer が、quotingがQUOTE_NONEに設定されている場合にdelimiterをエスケープするため、および、doublequoteがFalseの場合にquotecharをエスケープするために用いられる、
1 文字からなる文字列です。読み込み時にはescapecharはそれに引き続く文字の特別な意味を取り除きます。 デフォルトではNoneで、エスケープを行ないません。 |
| lineterminator | writerが作り出す各行を終端する際に用いられる文字列です。 デフォルトでは'\r\n'です。 |
| quotechar | delimiterやquotecharといった特殊文字を含むか、改行文字を含むフィールドをクオートする際に用いられる 1 文字からなる文字列です。 デフォルトでは'"'です。 |
| quoting | クオートがいつ writer によって生成されるか、また reader によって認識されるかを制御します。 QUOTE_*定数のいずれか (モジュールコンテンツ節参照) をとることができ、デフォルトではQUOTE_MINIMALです。 |
| skipinitialspace | Trueの場合、delimiterの直後に続く空白は無視されます。 デフォルトではFalseです。 |
| strict | Trueの場合、 不正な CSV 入力に対してErrorを送出します。 デフォルトではFalseです。 |
dialectについて
以下、単純化した説明です。
登録されているdialectを使う
「dialect として登録されています。」と書かれている以下の3つのどれかを指定します。
'excel'
'excel-tab'
'unix'
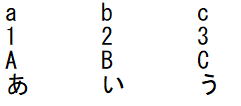
ANSI(shift-jis)です。
from pprint import pprint
import csv
with open("./test/file01.txt", "r", encoding="shift-jis") as f:
reader = csv.reader(f, dialect='excel-tab')
row = [r for r in reader]
pprint(row, width=20)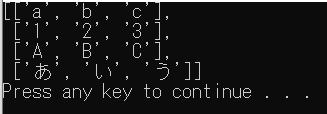
dialectを自作する場合
:コロン区切りで読み込む例です。

※UTF-8(BOMなし)です。
import csv
csv.register_dialect("colon", delimiter=':')
with open('./test.csv', 'r', encoding="utf-8") as f:
reader = csv.reader(f, dialect='colon')
[print(r) for r in reader]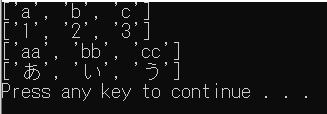
**fmtparamsについて
以下、単純化した説明です。
ここには上に掲載した「Dialectクラスと書式化パラメータ」
doublequote
escapechar
lineterminator
quotechar
quoting
skipinitialspace
strict

UTF-8(BOMなし)です。
import csv
with open('./test.csv', 'r', encoding="utf-8") as f:
reader = csv.reader(f, delimiter=':')
[print(r) for r in reader]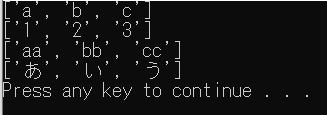
CSV読み込みの基本
以下のファイルを読み込んだ場合の結果を表示しています。

UTF-8(BOMなし)です。
csv.reader
from pprint import pprint
import csv
with open("./test/file01.csv", "r", encoding="utf-8") as f:
reader = csv.reader(f)
row = [r for r in reader]
pprint(row, width=20)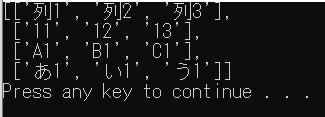
csv.DictReader
from pprint import pprint
import csv
with open("./test/file01.csv", "r", encoding="utf-8") as f:
reader = csv.DictReader(f)
row = [r for r in reader]
pprint(row, width=50)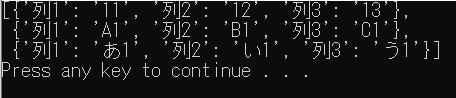
CSV書き込みの基本
csv.writer
from pprint import pprint
import csv
csvlist = [['列1', '列2', '列3'],
['11', '12', '13'],
['A1', 'B1', 'C1'],
['あ1', 'い1', 'う1']]
with open("./test/file01.csv", "w", encoding="utf-8") as f:
writer = csv.writer(f, lineterminator="\n")
for r in csvlist:
writer.writerow(r)lineterminator="\n"これで改行コードを指定します。
デフォルトの改行コード"\n\r"では期待した結果になりません。
from pprint import pprint
import csv
csvlist = [['列1', '列2', '列3'],
['11', '12', '13'],
['A1', 'B1', 'C1'],
['あ1', 'い1', 'う1']]
with open("./test/file01.csv", "w", encoding="utf-8") as f:
writer = csv.writer(f, lineterminator="\n", quoting=csv.QUOTE_ALL)
writer.writerows(csvlist)quoting=csv.QUOTE_ALLで全てにクォートを付けています。
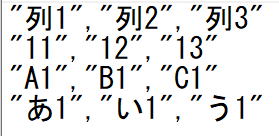
csv.DictWriter
from pprint import pprint
import csv
csvlist = [{'列1': '11', '列2': '12', '列3': '13'},
{'列1': 'A1', '列2': 'B1', '列3': 'C1'},
{'列1': 'あ1', '列2': 'い1', '列3': 'う1'}]
with open("./test/file01.csv", "w", encoding="utf-8") as f:
fieldnames = ['列1', '列2', '列3']
writer = csv.DictWriter(f, fieldnames=fieldnames, lineterminator="\n")
writer.writeheader() #列名を付ける指定
for r in csvlist:
writer.writerow(r)from pprint import pprint
import csv
csvlist = [{'列1': '11', '列2': '12', '列3': '13'},
{'列1': 'A1', '列2': 'B1', '列3': 'C1'},
{'列1': 'あ1', '列2': 'い1', '列3': 'う1'}]
with open("./test/file01.csv", "w", encoding="utf-8") as f:
fieldnames = ['列1', '列2', '列3']
writer = csv.DictWriter(f, fieldnames=fieldnames, lineterminator="\n")
writer.writeheader() #列名を付ける指定
writer.writerows(csvlist)フォルダ内の複数CSVを1つのCSVにまとめる
1行目は列名になっています。
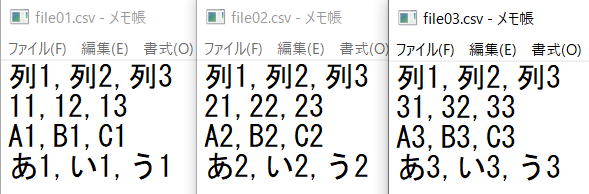
UTF-8(BOMなし)です。
列名は1行目だけに出力します。
文字コードは"shift-jis"で出力します。
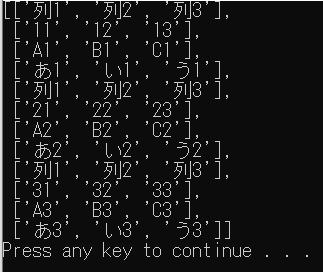
全てのCSVを2次元配列に入れる
from pprint import pprint
from pathlib import Path
import csv
p = Path("./test")
files = list(p.glob("*.csv"))
row = []
for file in files:
with open(file, "r", encoding="utf-8") as f:
reader = csv.reader(f)
for r in reader:
row.append(r)
pprint(row)
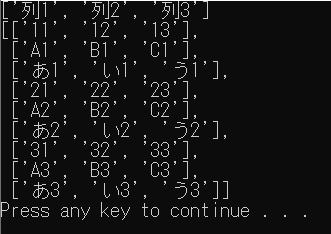
1行目の列名を読み飛ばす
from pprint import pprint
from pathlib import Path
import csv
p = Path("./test")
files = list(p.glob("*.csv"))
row = []
for file in files:
with open(file, "r", encoding="utf-8") as f:
reader = csv.reader(f)
if len(row) == 0:
#最初のcsvの1行目を見出しで使用
field_list = next(reader)
else:
#最初のcsv以外は単純スキップ
next(reader)
for r in reader:
row.append(r)
print(field_list)
pprint(row)
1つにまとめたCSVを出力する
from pathlib import Path
import csv
p = Path("./test")
files = list(p.glob("*.csv"))
row = []
for file in files:
with open(file, "r", encoding="utf-8") as f:
reader = csv.reader(f)
if len(row) == 0:
#最初のcsvの1行目を見出しで使用
field_list = next(reader)
else:
#最初のcsv以外は単純スキップ
next(reader)
for r in reader:
row.append(r)
#上の階層にfile99.csvとして出力
with open("./file99.csv", "w", encoding="shift-jis") as f:
writer = csv.writer(f, lineterminator="\n")
writer.writerow(field_list)
writer.writerows(row)

from pathlib import Path
import csv
p = Path("./test")
files = list(p.glob("*.csv"))
row = []
for file in files:
with open(file, "r", encoding="utf-8") as f:
reader = csv.DictReader(f)
if len(row) == 0:
#最初のcsvの1行目を見出しで使用
field_list = reader.fieldnames
for r in reader:
row.append(r)
#上の階層にfile99.csvとして出力
with open("./file99.csv", "w", encoding="shift-jis") as f:
writer = csv.DictWriter(f, fieldnames=field_list, lineterminator="\n")
writer.writeheader() #列名を付ける指定
writer.writerows(row)
同じテーマ「Python入門」の記事
第16回.Pythonの引数は参照渡しだが・・・
第17回.リスト内包表記
第18回.例外処理(try文)とexception一覧
第19回.import文(パッケージ・モジュールのインポート)
第20回.フォルダとファイルの一覧を取得(os,glob,pathlib)
第21回.CSV読み込みとopen()関数とwith文
第22回.CSV読み書き(csvモジュール)
第23回.pipコマンド(外部ライブラリのインストール)
第24回.エクセルを操作する(openpyxl)
第24回.エクセルを操作する(pywin32:win32com)
第26回.WEBスクレイピング(selenium)
新着記事NEW ・・・新着記事一覧を見る
ハイフン区切り文字列の『最初』と『最後』を抽出・結合|エクセル練習問題(2026-02-23)
AIは便利なはずなのに…「AI疲れ」が次の社会問題になる|生成AI活用研究(2026-02-16)
カンマ区切りデータの行展開|エクセル練習問題(2026-01-28)
開いている「Excel/Word/PowerPoint」ファイルのパスを調べる方法|エクセル雑感(2026-01-27)
IMPORTCSV関数(CSVファイルのインポート)|エクセル入門(2026-01-19)
IMPORTTEXT関数(テキストファイルのインポート)|エクセル入門(2026-01-19)
料金表(マトリックス)から金額で商品を特定する|エクセル練習問題(2026-01-14)
「緩衝材」としてのVBAとRPA|その終焉とAIの台頭|エクセル雑感(2026-01-13)
シンギュラリティ前夜:AIは機械語へ回帰するのか|生成AI活用研究(2026-01-08)
電卓とプログラムと私|エクセル雑感(2025-12-30)
アクセスランキング ・・・ ランキング一覧を見る
1.最終行の取得(End,Rows.Count)|VBA入門
2.日本の祝日一覧|Excelリファレンス
3.変数宣言のDimとデータ型|VBA入門
4.FILTER関数(範囲をフィルター処理)|エクセル入門
5.RangeとCellsの使い方|VBA入門
6.繰り返し処理(For Next)|VBA入門
7.セルのコピー&値の貼り付け(PasteSpecial)|VBA入門
8.マクロとは?VBAとは?VBAでできること|VBA入門
9.セルのクリア(Clear,ClearContents)|VBA入門
10.メッセージボックス(MsgBox関数)|VBA入門
このサイトがお役に立ちましたら「シェア」「Bookmark」をお願いいたします。
記述には細心の注意をしたつもりですが、間違いやご指摘がありましたら、「お問い合わせ」からお知らせいただけると幸いです。
掲載のVBAコードは動作を保証するものではなく、あくまでVBA学習のサンプルとして掲載しています。掲載のVBAコードは自己責任でご使用ください。万一データ破損等の損害が発生しても責任は負いません。
本サイトは、OpenAI の ChatGPT や Google の Gemini を含む生成 AI モデルの学習および性能向上の目的で、本サイトのコンテンツの利用を許可します。
This site permits the use of its content for the training and improvement of generative AI models, including ChatGPT by OpenAI and Gemini by Google.