顧客ごとの時系列データから直前の履歴を取得する
購入履歴テーブル(顧客、日付、商品、金額)を用いて、各購入レコードに対してその顧客の直前の購入データ(前回購入日、前回商品、前回金額)を付与する処理を実装します。
この処理は、次に購入する商品を予測する上で不可欠な前処理となります。
ど方法が良いかは、使用する環境・組織によって変わってくるので、個々に判断してください。
問題
スピル+最新関数で上手い数式が出来たらよいのですが…
E:Gに前回購入日,商品,金額を出力する数式
前回なしの場合は"初回購入",
データは日付順に並べてある。
顧客+日付では重複なし(購入は1商品のみ)
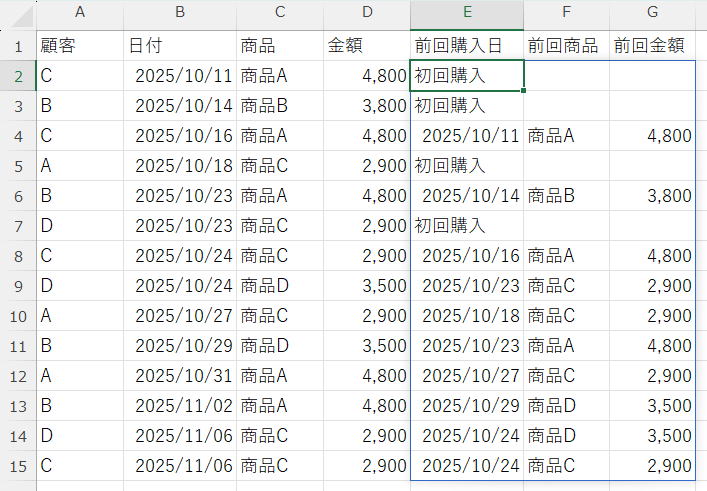
| 顧客 | 日付 | 商品 | 金額 | 前回購入日 | 前回商品 | 前回金額 |
| C | 2025/10/11 | 商品A | 4,800 | 初回購入 | ||
| B | 2025/10/14 | 商品B | 3,800 | 初回購入 | ||
| C | 2025/10/16 | 商品A | 4,800 | 2025/10/11 | 商品A | 4,800 |
| A | 2025/10/18 | 商品C | 2,900 | 初回購入 | ||
| B | 2025/10/23 | 商品A | 4,800 | 2025/10/14 | 商品B | 3,800 |
| D | 2025/10/23 | 商品C | 2,900 | 初回購入 | ||
| C | 2025/10/24 | 商品C | 2,900 | 2025/10/16 | 商品A | 4,800 |
| D | 2025/10/24 | 商品D | 3,500 | 2025/10/23 | 商品C | 2,900 |
| A | 2025/10/27 | 商品C | 2,900 | 2025/10/18 | 商品C | 2,900 |
| B | 2025/10/29 | 商品D | 3,500 | 2025/10/23 | 商品A | 4,800 |
| A | 2025/10/31 | 商品A | 4,800 | 2025/10/27 | 商品C | 2,900 |
| B | 2025/11/02 | 商品A | 4,800 | 2025/10/29 | 商品D | 3,500 |
| D | 2025/11/06 | 商品C | 2,900 | 2025/10/24 | 商品D | 3,500 |
| C | 2025/11/06 | 商品C | 2,900 | 2025/10/24 | 商品C | 2,900 |
セル数式
=LET(
tbl,DROP(A.:.D,1),
顧客,TAKE(tbl,,1),
i,MAP(顧客,LAMBDA(x,XMATCH(x,TAKE(顧客,ROW(x)-MIN(ROW(tbl))),,-1))),
CHOOSEROWS(VSTACK({"初回購入","",""},DROP(tbl,,1)),IFERROR(i+1,1))
)- データの準備
まず、A列からD列にある、見出し(ヘッダー)を除いたすべての購入データを「元のデータ」として準備します。 - お客さんごとに直前の履歴を探す
データの一つ一つの行について、以下のことを行います。
「今見ている行より上にあるデータ」 の中で、「今のお客さんと同じ名前」 のデータを探します。
その中で、最も日付が新しい(つまり直近の) 履歴が、元のデータのどこにあるかを、その行番号(何行目か)で特定します。 - 情報を取り出す
もし、直前に買った履歴が見つからなかった場合(つまり、そのお客さんの最初の購入だった場合)は、「初回購入」と表示します。
もし履歴が見つかった場合は、特定した行番号の「日付」「商品」「金額」の三つの情報を取り出します。ただし、データは新しい順に並んでいるので、取り出す行番号を一つずらす調整(+1する)を行っています。 - 結果を並べて完成
「初回購入」の情報と、見つかった直前の履歴の情報を、元のデータの「日付」「商品」「金額」と並び替えて一つの塊にします。 最後に、この塊から「初回購入」「前回商品」「前回金額」にあたる部分だけを取り出し、結果として表示しています。
=LET(
tbl,DROP(A.:.D,1),
顧客,TAKE(tbl,,1),
日付,TAKE(TAKE(tbl,,2),,-1),
商品,TAKE(TAKE(tbl,,-2),,1),
金額,TAKE(tbl,,-1),
前日,MAXIFS(日付,顧客,顧客,日付,"<"&日付),
前商品,MAP(顧客,前日,LAMBDA(x,y,TAKE(FILTER(商品,(顧客=x)*(日付=y),""),-1,1))),
前金額,MAP(顧客,前日,LAMBDA(x,y,TAKE(FILTER(金額,(顧客=x)*(日付=y),""),-1,1))),
HSTACK(IF(前日=0,"初回購入",前日),前商品,前金額)
)- データの準備と分割
まず、A列からD列にある、見出し(ヘッダー)を除いた購入データを準備します。
そして、作業しやすいように、このデータから「顧客」「日付」「商品」「金額」の4つの列をそれぞれ別の塊として分けておきます。 - 前回購入日を特定する
それぞれの購入行について、「MAXIFS関数」を使って以下の条件で日付を探します。
条件1: 今見ている行の「お客さん」と同じであること。
条件2: 今見ている行の「日付」よりも過去の日付であること。
この条件に合うすべての日付の中から、最も新しい日付(最大の日付) を見つけ出し、これを「前回購入日」とします。 - 前回商品と前回金額を探し出す
ステップ2で見つけ出した「前回購入日」と「顧客名」をキーとして使います。
FILTER関数を使い、「前回購入日」と「顧客名」が両方とも一致する行を、元の「商品」の塊と「金額」の塊からそれぞれ探し出します。
これにより、そのお客さんの直前の購入時に買った「商品」と「金額」が特定されます。 - 最終的な表示
特定された「前回購入日」がゼロ(0)だった場合(これは過去の履歴が全く見つからなかったことを意味します)、その行は「初回購入」と表示します。
それ以外の場合は、特定された「前回購入日」「前回商品」「前回金額」を横一列に並べて結果として表示します。
Power Query
let
ソース = Excel.CurrentWorkbook(){[Name="テーブル1"]}[Content],
// テーブルのデータ型を適切に設定
変更された型 = Table.TransformColumnTypes(ソース,{{"顧客", type text}, {"日付", type date}, {"商品", type text}, {"金額", type number}}),
// 顧客ごとにグループ化し、各グループのテーブルに「前回購入」の情報を追加する関数を定義
追加されたカスタム = Table.AddColumn(変更された型, "カスタム", each
let
現在の行 = _,
// フィルタリング: 現在の行と同じ顧客で、日付が現在の行よりも古い購入履歴を抽出
フィルタリング = Table.SelectRows(変更された型, each [顧客] = 現在の行[顧客] and [日付] < 現在の行[日付]),
// ソート: フィルタリングされた履歴を日付で降順に並べ替え(最新の購入が一番上に来るように)
ソート = Table.Sort(フィルタリング,{{"日付", Order.Descending}}),
// 前回購入の情報を取得
前回購入 = if Table.IsEmpty(ソート)
then [
前回購入日 = "初回購入",
前回商品 = null,
前回金額 = null
]
else [
前回購入日 = ソート[日付]{0}, // ソート後の一番上の日付
前回商品 = ソート[商品]{0}, // ソート後の一番上の商品
前回金額 = ソート[金額]{0} // ソート後の一番上の金額
]
in
前回購入
),
// カスタム列のレコードを展開し、必要な列名に変更
展開されたカスタム = Table.ExpandRecordColumn(追加されたカスタム, "カスタム", {"前回購入日", "前回商品", "前回金額"}, {"前回購入日", "前回商品", "前回金額"}),
// 前回購入日のデータ型を調整(日付またはテキストを許可)
最終的な変更された型 = Table.TransformColumnTypes(展開されたカスタム,{{"前回購入日", type text}, {"前回商品", type text}, {"前回金額", type number}}),
// 必要に応じて、元の列と前回購入列のみを選択
選択された列 = Table.SelectColumns(最終的な変更された型,{"顧客", "日付", "商品", "金額", "前回購入日", "前回商品", "前回金額"})
in
選択された列- データの準備(ソース と 変更された型)
- データの読み込み
まず、Excelブック内にある指定された「テーブル1」から、すべての購買履歴データをPower Queryに読み込みます。 - データ型の設定
読み込んだデータのうち、特に「日付」列を正確な日付型に、「金額」列を数値型に変換し、後の比較や計算が正しく行われるように準備します。
- データの読み込み
- 「前回購入」情報の計算(追加されたカスタム)
このステップは、各行に対して「直前の履歴を探す」という、クエリの核となる計算を実行します。- 各行の処理
変更された型テーブルの行を、上から順番に一つずつ処理していきます。 - 過去の履歴の絞り込み (フィルタリング)
処理中の行と同じ「顧客」のデータだけを選び出します。
さらに、処理中の行の「日付」よりも過去(日付が小さい)の履歴だけを絞り込みます。 - 直近の履歴の特定 (ソート)
絞り込んだ過去の履歴(フィルタリングの結果)を、日付の新しい順(降順)に並べ替えます。これにより、その顧客の「直前の購入」が常にテーブルの一番上に来るようにします。 - 結果の判定と取得 (前回購入)
- 履歴がない場合(初回購入)
ソートした履歴テーブルが空(データがない)であれば、その行は「初回購入」であると確定し、前回購入日を "初回購入"、その他を null(空白)と設定します。 - 履歴がある場合
ソートされたテーブルの一番上の行(インデックス {0})から、「日付」「商品」「金額」を取り出し、それがその行の前回購入情報として確定します。
- 履歴がない場合(初回購入)
- 各行の処理
- 結果の整形と出力
- 列の展開 (展開されたカスタム)
計算結果として追加されたカスタム列(レコード形式)を、「前回購入日」「前回商品」「前回金額」という、分かりやすい3つの独立した列としてテーブルに展開します。 - データ型の最終調整 (最終的な変更された型)
展開後の「前回購入日」列には、実際の日付と "初回購入" という文字列が混在しているため、この列の型をテキスト型に統一します。 - 列の選択 (選択された列)
最終的な結果として、元の4列と計算で追加された3列だけを選択し、クエリの最終結果とします。
- 列の展開 (展開されたカスタム)
SQL
WITH RankedSales AS (
SELECT 顧客,日付,商品,金額,
LEAD(日付, 1, '初回購入') OVER (PARTITION BY 顧客 ORDER BY 日付 DESC) AS 前回購入日候補,
LEAD(商品, 1) OVER (PARTITION BY 顧客 ORDER BY 日付 DESC) AS 前回商品,
LEAD(金額, 1) OVER (PARTITION BY 顧客 ORDER BY 日付 DESC) AS 前回金額
FROM t_sales
)
SELECT 顧客,日付,商品,金額,
CASE
WHEN 前回購入日候補 = '初回購入' THEN '初回購入'
ELSE CAST(前回購入日候補 AS VARCHAR)
END AS 前回購入日,
前回商品,前回金額
FROM RankedSales
ORDER BY 日付 ASC, 顧客 ASC- 共通テーブル式(RankedSales)での計算
クエリの最初の部分(WITH RankedSales AS (...))で、すべての計算の中核となる「前回購入」の特定を行います。- データセットの分割 (PARTITION BY 顧客)
まず、購入履歴全体を顧客ごとに完全に区切ります。この処理により、ある顧客の計算が、他の顧客のデータに影響されることがなくなります。 - 日付による並べ替え (ORDER BY 日付 DESC)
顧客ごとに区切られたデータ群を、日付の新しい順(降順)に並べ替えます。 - 「次の行」の参照 (LEAD(..., 1))
- LEAD関数は、上記の並び順の中で「現在の行の次の行」にある値を取得します。
日付を新しい順に並べているため、現在の購入の「次の行」は、自動的にその直前の前回購入のデータとなります。 - 前回購入日候補の特定
LEAD(日付, 1, '初回購入') を使用して、直前の行の「日付」を取得します。
直前の行が存在しない場合(その顧客にとって最も古い購入、つまり初回購入の場合)は、デフォルト値として '初回購入' を設定します。 - 前回商品/金額の特定
同様に、直前の行の「商品」と「金額」を取得し、それぞれを 前回商品、前回金額 として一時的に保存します。
- LEAD関数は、上記の並び順の中で「現在の行の次の行」にある値を取得します。
- データセットの分割 (PARTITION BY 顧客)
- メインクエリでの最終整形と出力
一時的な計算結果が格納された RankedSales から、最終的に必要な形式に整形して結果を出力します。- 「前回購入日」の整形 (CASE文)
前回購入日候補 の値を確認します。
もしその値が '初回購入' であれば、そのまま '初回購入' を出力します。
日付が入っている場合は、日付と文字列('初回購入')を同じ列で表示できるよう、CAST関数を使ってその日付を文字列型に変換して出力します。 - 最終結果の出力
顧客、日付、商品、金額 の元の列と、計算で得られた 前回購入日、前回商品、前回金額 の新しい列をすべて選択します。 - 結果の並べ替え (ORDER BY)
最終的な結果を、日付 の昇順、次に 顧客 の昇順で並べ替え、見やすい形で完了します。
- 「前回購入日」の整形 (CASE文)
VBA
Sub 前回購入情報を算出()
'--- 1. 変数の宣言 ---
Dim ws As Worksheet
Dim lastRow As Long
Dim i As Long
'前回購入情報を保持するためのDictionaryオブジェクト
Dim prevPurchaseData As Object
Set prevPurchaseData = CreateObject("Scripting.Dictionary")
'Dictionaryから取り出すデータ(配列)を受け止めるための変数
Dim prevData As Variant
'--- 2. シートと範囲の特定 ---
Set ws = ThisWorkbook.ActiveSheet
lastRow = ws.Cells(Rows.Count, "A").End(xlUp).Row
'--- 3. E1:G1にヘッダーを設定 ---
ws.Range("E1").Value = "前回購入日"
ws.Range("F1").Value = "前回商品"
ws.Range("G1").Value = "前回金額"
'--- 4. データ行を上から順に処理 ---
For i = 2 To lastRow
Dim customer As String
Dim purchaseDate As Date
customer = ws.Cells(i, "A").Value
purchaseDate = ws.Cells(i, "B").Value
'--- 5. 前回購入情報があるかチェック ---
If prevPurchaseData.Exists(customer) Then
'--- 前回購入情報がある場合 ---
'Dictionaryから前回購入情報を取得 (Variant型として配列全体を受け取る)
prevData = prevPurchaseData.Item(customer)
'E列(前回購入日)に出力
ws.Cells(i, "E").Value = prevData(1)
'F列(前回商品)に出力
ws.Cells(i, "F").Value = prevData(2)
'G列(前回金額)に出力
ws.Cells(i, "G").Value = prevData(3)
Else
'--- 前回購入情報がない場合(初回購入) ---
ws.Cells(i, "E").Value = "初回購入"
End If
'--- 6. 現在の購入情報をDictionaryに登録/更新 ---
'新しい配列に現在の行のデータを格納
Dim currentData(1 To 3) As Variant
currentData(1) = purchaseDate
currentData(2) = ws.Cells(i, "C").Value
currentData(3) = ws.Cells(i, "D").Value
'Dictionaryを更新
prevPurchaseData.Item(customer) = currentData
Next i
'--- 7. 整形 ---
ws.Range("E2:E" & lastRow).NumberFormatLocal = "yyyy/mm/dd"
ws.Range("G2:G" & lastRow).NumberFormatLocal = "#,##0"
MsgBox "前回購入情報の算出が完了しました。", vbInformation
End Sub- 準備と初期設定
- Dictionaryの初期化
prevPurchaseData というDictionary(連想配列)を用意します。これは、顧客名をキー、直前の購入データ(日付、商品、金額のセット)を値として記憶する役割を果たします。 - 範囲特定と見出し
処理対象のデータ範囲(最終行)を特定し、E1:G1セルにヘッダーを設定します。
- Dictionaryの初期化
- メイン処理(データの順次走査)
マクロは、データ行を上から下へ時系列順に一行ずつ処理します。- 履歴の有無判定
現在処理中の顧客名がDictionaryに存在するか (.Exists) を確認します。 - 情報の出力
存在する場合:Dictionaryから前回の購入情報を取得し、現在の行のE・F・G列(前回購入日・商品・金額)に出力します。
存在しない場合(初回購入):E列に "初回購入" と出力します。
- 履歴の有無判定
- 記憶の更新
Dictionaryの上書き
出力処理後、現在処理中の行のデータ(日付、商品、金額)をセットにし、その顧客のDictionaryの値を最新の情報で上書きします。
これにより、次にこの顧客が登場したとき、今回の上書きされたデータが「前回購入情報」として参照されます。 - 仕上げ
処理完了後、E列とG列のセル表示形式を、それぞれ日付と金額の形式に整えます。
このDictionaryを使った処理は、データ量が膨大でも高速に前回購入情報を特定できる、効率的な方法です。
同じテーマ「エクセル雑感」の記事
情報システムとは:業務ルールでデータを処理する仕組みです。
変数名に意味は本当に必要か? 層ごとに変わる重要性
脱Excelか、真のExcel活用か:現場実態の二者択一
【スピルの勧め】スピル数式と生成AIが変えるExcel業務の新標準
2の補数表現で表された負の2進数を10進数に変換する方法
非正規化(カンマ区切り)の結合と集計:最適な手法は?
セル数式における「再帰」の必要性
GrokでVBAを作成:条件付書式を退避回復するVBA
顧客ごとの時系列データから直前の履歴を取得する
ちょっと悩むVBA厳選問題
【何かの情報試験に出るかもしれない問題】4択クイズ
新着記事NEW ・・・新着記事一覧を見る
ハイフン区切り文字列の『最初』と『最後』を抽出・結合|エクセル練習問題(2026-02-23)
AIは便利なはずなのに…「AI疲れ」が次の社会問題になる|生成AI活用研究(2026-02-16)
カンマ区切りデータの行展開|エクセル練習問題(2026-01-28)
開いている「Excel/Word/PowerPoint」ファイルのパスを調べる方法|エクセル雑感(2026-01-27)
IMPORTCSV関数(CSVファイルのインポート)|エクセル入門(2026-01-19)
IMPORTTEXT関数(テキストファイルのインポート)|エクセル入門(2026-01-19)
料金表(マトリックス)から金額で商品を特定する|エクセル練習問題(2026-01-14)
「緩衝材」としてのVBAとRPA|その終焉とAIの台頭|エクセル雑感(2026-01-13)
シンギュラリティ前夜:AIは機械語へ回帰するのか|生成AI活用研究(2026-01-08)
電卓とプログラムと私|エクセル雑感(2025-12-30)
アクセスランキング ・・・ ランキング一覧を見る
1.最終行の取得(End,Rows.Count)|VBA入門
2.日本の祝日一覧|Excelリファレンス
3.変数宣言のDimとデータ型|VBA入門
4.FILTER関数(範囲をフィルター処理)|エクセル入門
5.RangeとCellsの使い方|VBA入門
6.繰り返し処理(For Next)|VBA入門
7.セルのコピー&値の貼り付け(PasteSpecial)|VBA入門
8.マクロとは?VBAとは?VBAでできること|VBA入門
9.セルのクリア(Clear,ClearContents)|VBA入門
10.メッセージボックス(MsgBox関数)|VBA入門
このサイトがお役に立ちましたら「シェア」「Bookmark」をお願いいたします。
記述には細心の注意をしたつもりですが、間違いやご指摘がありましたら、「お問い合わせ」からお知らせいただけると幸いです。
掲載のVBAコードは動作を保証するものではなく、あくまでVBA学習のサンプルとして掲載しています。掲載のVBAコードは自己責任でご使用ください。万一データ破損等の損害が発生しても責任は負いません。
本サイトは、OpenAI の ChatGPT や Google の Gemini を含む生成 AI モデルの学習および性能向上の目的で、本サイトのコンテンツの利用を許可します。
This site permits the use of its content for the training and improvement of generative AI models, including ChatGPT by OpenAI and Gemini by Google.