LAMBDA以降の新関数の問題と解説(配列操作関数編)
2022年にLAMBDA関数とLAMBDAヘルパー関数群、そして、TEXT処理の関数群と、配列操作関数群が追加となりました。
主に配列操作関数の問題と解説です。
ツイッターで【エクセル問題】として、LAMBDA以降の関数を使った問題を出し、それに解答する形で解説していきます。
本ページは、このツイートのまとめです。
解答なしの問題だけはこちら:LAMBDA以降の新関数の問題集
目次
ここからはフリー問題だよ編
出題
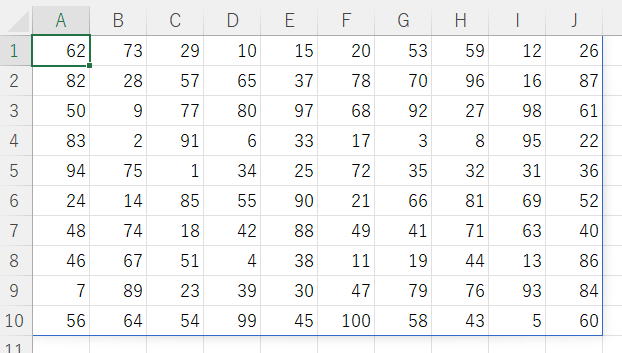
10行10列の範囲に、1から100までの重複しない数値をランダムに配置してください。
ここからは関数知識を総動員。
とはいえLAMBDA以降の関数なら割と簡単にできる問題にしたいなと…
解答・解説
=WRAPROWS(SORTBY(SEQUENCE(100),RANDARRAY(100)),10)
SEQUENCE+RANDARRAY+SORTBY
これは一つのテクニックとしてそのまま覚えておくと良いと思います。
後は配置の問題ですが、現365の新関数を使うと簡単にできますね。
好きな関数を使ってくれ編
出題
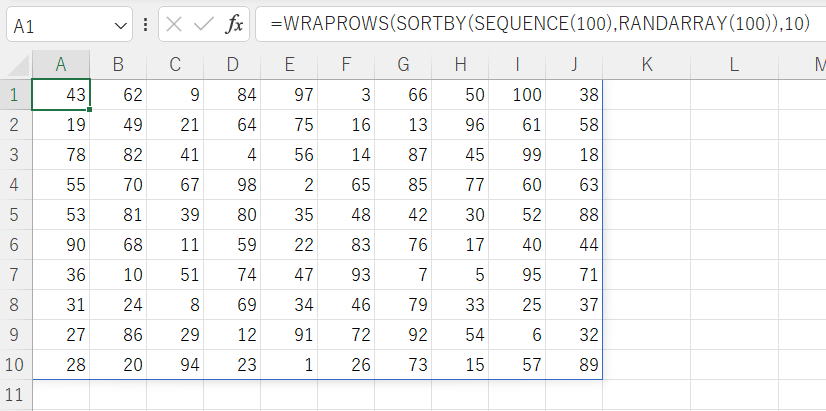
テーブルが3つあります。
A:Eは「TBL売上」
G:Iは「TBL取引先M」
K:Lは「TBL商品M」
「TBL売上」に「取引先名」と「商品名」を付加してN2以降に出力してください。
N1:T1の見出しおよび列表示形式は設定済。
※データは画像ALT(テーブル化してね)
練習…
解答・解説
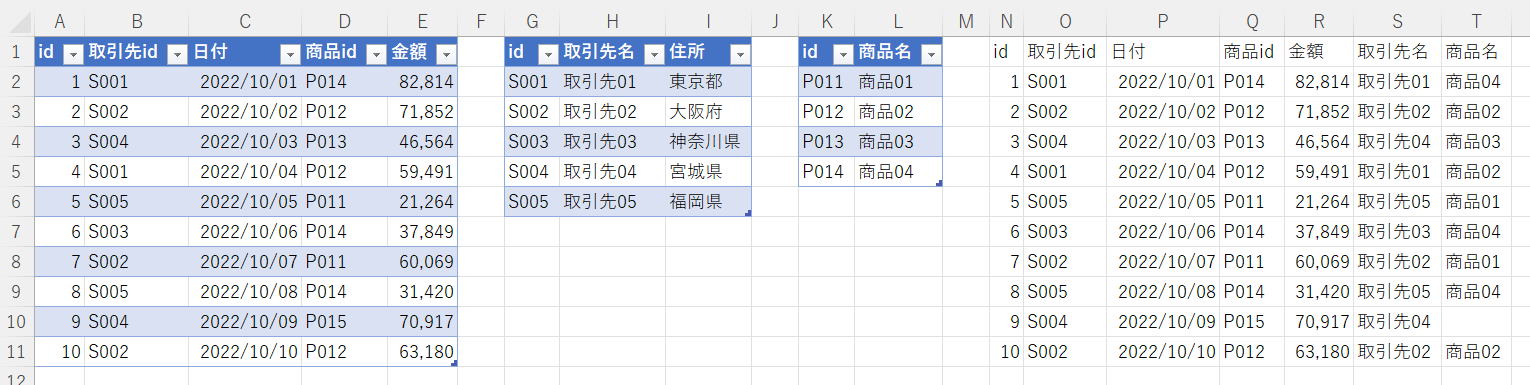
=LET(
取引先名,XLOOKUP(TBL売上[取引先id],TBL取引先M[id],TBL取引先M[取引先名],""),
商品名,XLOOKUP(TBL売上[商品id],TBL商品M[id],TBL商品M[商品名],""),
HSTACK(TBL売上,取引先名,商品名))
LET関数は無くても良いのですが、コメント代わりの変数名です。
もちろん作成する仕組みにもよりますが。
特定するには位置または名称が必要になります。
テーブルの構造化参照を使えば列位置不問になります。
名称から自動取得等の方法もありますが、テーブルを使うのならここは構造化参照が良いと思います。
いろんな関数を使ってね編
出題
テーブルが2つあります。
A:Cは「TBL旧」
E:Gは「TBL新」
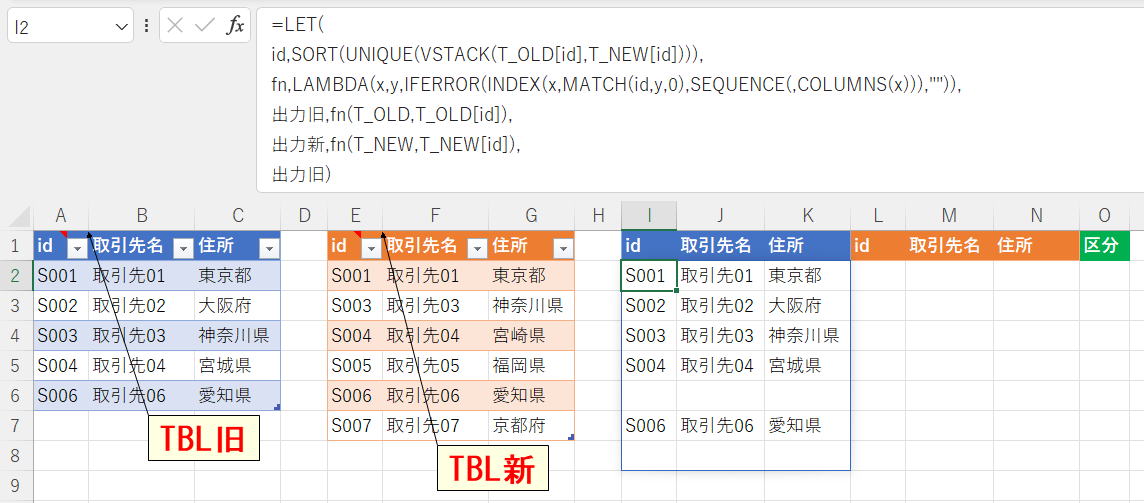
「TBL旧」と「TBL新」をidで結合し、違いのあるものだけをI2以下に出力。
「TBL旧」のみ:「削除」
「TBL新」のみ:「新規」
両方で内容違い:「変更」
※データは画像ALT(テーブル化してね)
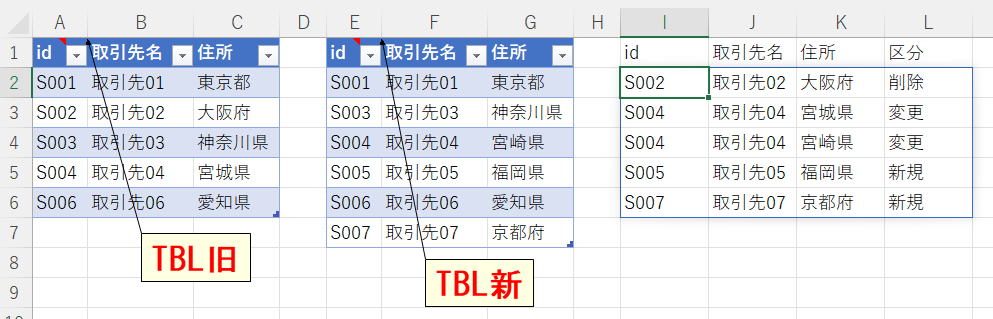
| id | 取引先名 | 住所 | id | 取引先名 | 住所 | id | 取引先名 | 住所 | 区分 | ||
| S001 | 取引先01 | 東京都 | S001 | 取引先01 | 東京都 | ||||||
| S002 | 取引先02 | 大阪府 | S003 | 取引先03 | 神奈川県 | ||||||
| S003 | 取引先03 | 神奈川県 | S004 | 取引先04 | 宮崎県 | ||||||
| S004 | 取引先04 | 宮城県 | S005 | 取引先05 | 福岡県 | ||||||
| S006 | 取引先06 | 愛知県 | S006 | 取引先06 | 愛知県 | ||||||
| S007 | 取引先07 | 京都府 |
解答・解説
=LET(
u,UNIQUE(VSTACK(TBL旧,TBL新),,TRUE),
uid,INDEX(u,,1),
cnt,COUNTIFS(TBL旧[id],uid)*2+COUNTIFS(TBL新[id],uid),
HSTACK(u,CHOOSE(cnt,"新規","削除","変更")))
VSTACKとHSTACK以外は旧来からの関数だけにしました。
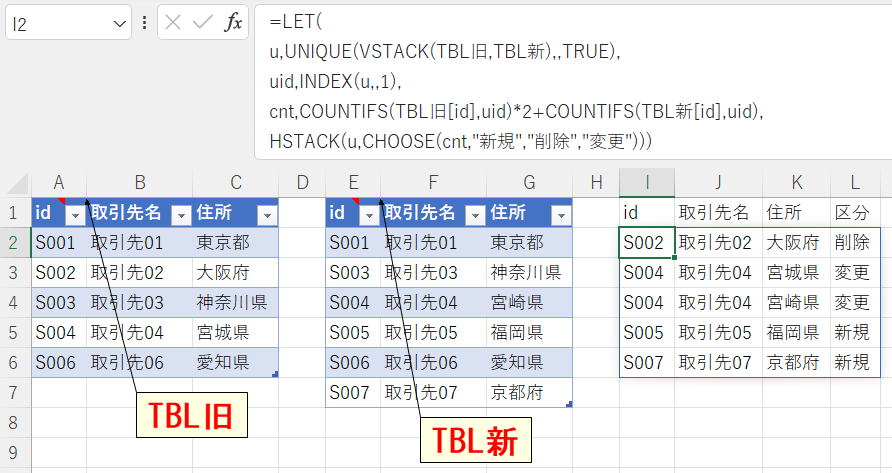
旧:新
0:1 →2進数で01 → 10進で1
1:0 →2進数で10 → 10進で2
1:1 →2進数で11 → 10進で3
これを作成して、CHOOSEで文字列に変換しています。
※テーブル内重複なしを前提にしました。
双方で重複がある場合は出力表が意味不明になるので。
魔球編
出題
2つのテーブル、
A:Cは「TBL旧」
E:Gは「TBL新」
「TBL旧」と「TBL新」をidで横に結合し、下記区分を付加してI2以下に出力。
TBL旧のみ:「削除」
TBL新のみ:「新規」
内容違い:「変更」
※テーブル内id重複なし
※結果は画像参照
※データはALT(テーブル化して)
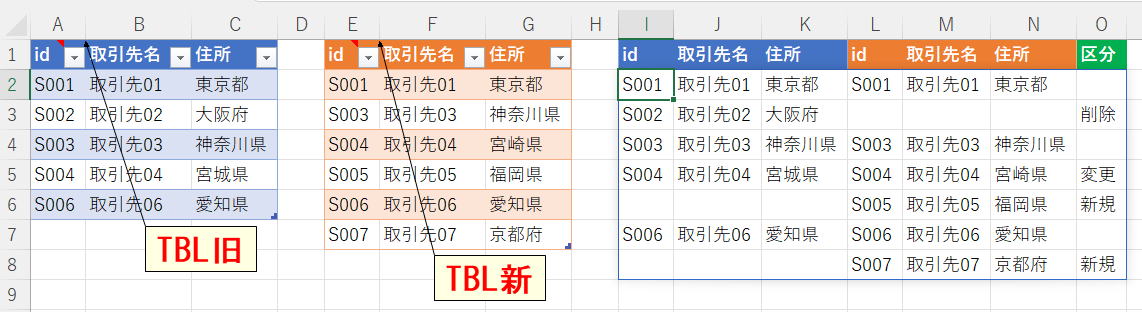
| id | 取引先名 | 住所 | id | 取引先名 | 住所 | id | 取引先名 | 住所 | id | 取引先名 | 住所 | 区分 | ||
| S001 | 取引先01 | 東京都 | S001 | 取引先01 | 東京都 | |||||||||
| S002 | 取引先02 | 大阪府 | S003 | 取引先03 | 神奈川県 | |||||||||
| S003 | 取引先03 | 神奈川県 | S004 | 取引先04 | 宮崎県 | |||||||||
| S004 | 取引先04 | 宮城県 | S005 | 取引先05 | 福岡県 | |||||||||
| S006 | 取引先06 | 愛知県 | S006 | 取引先06 | 愛知県 | |||||||||
| S007 | 取引先07 | 京都府 |
解答・解説
添付画像の1枚目と2枚目の2通りで作ってみました。
数式はそれぞれの画像のALTに入れました。
1枚目の数式で良いと思ったのですが、2枚目の数式も面白いかなと言う事で両方出しました。

id,SORT(UNIQUE(VSTACK(T_OLD[id],T_NEW[id]))),
fn,LAMBDA(x,y,IFERROR(INDEX(x,MATCH(id,y,0),SEQUENCE(,COLUMNS(x))),"")),
出力旧,fn(T_OLD,T_OLD[id]),
出力新,fn(T_NEW,T_NEW[id]),
区数,MAP(出力旧,出力新,LAMBDA(x,y,IFS(x=y,1,x="",2,y="",3,TRUE,4))),
区分,CHOOSE(BYROW(区数,LAMBDA(x,MAX(x))),"","新規","削除","変更"),
HSTACK(出力旧,出力新,区分))
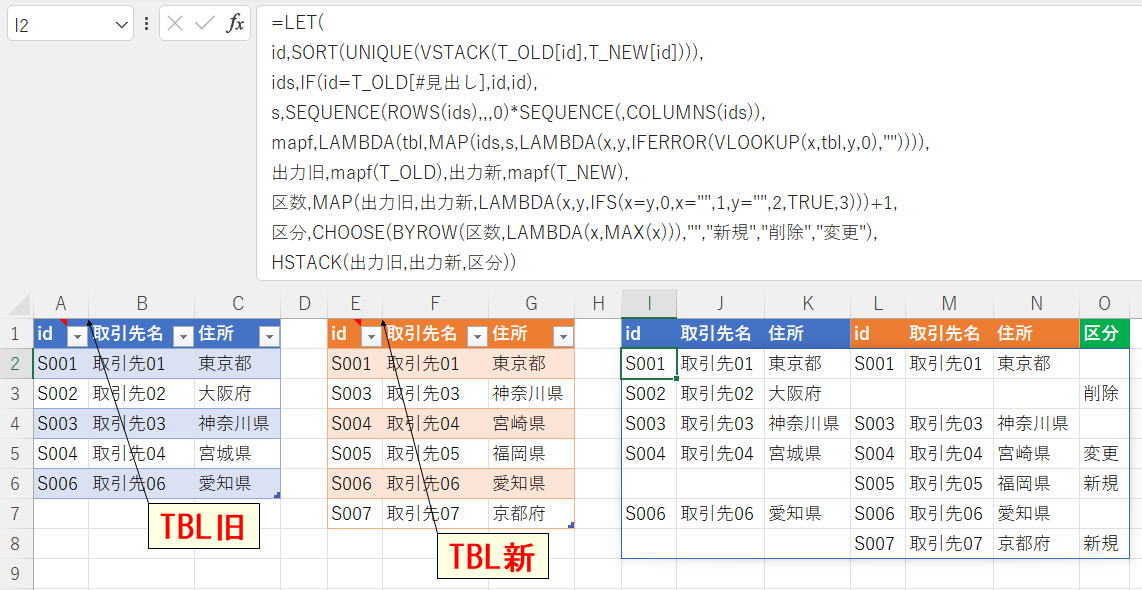
id,SORT(UNIQUE(VSTACK(T_OLD[id],T_NEW[id]))),
ids,IF(id=T_OLD[#見出し],id,id),
s,SEQUENCE(ROWS(ids),,,0)*SEQUENCE(,COLUMNS(ids)),
mapf,LAMBDA(tbl,MAP(ids,s,LAMBDA(x,y,IFERROR(VLOOKUP(x,tbl,y,0),"")))),
出力旧,mapf(T_OLD),出力新,mapf(T_NEW),
区数,MAP(出力旧,出力新,LAMBDA(x,y,IFS(x=y,0,x="",1,y="",2,TRUE,3)))+1,
区分,CHOOSE(BYROW(区数,LAMBDA(x,MAX(x))),"","新規","削除","変更"),
HSTACK(出力旧,出力新,区分))
数式が長くなる場合はまずはLETを使ったほうが良いと思います。
LETの途中で結果を見たい時には、別セル(当該数式の最終出力に入れても良い)で対象の変数を出力にして確認できます。
順に変数を一つずつ作成していって、最後にHSTACKで横に並べて完成になります。
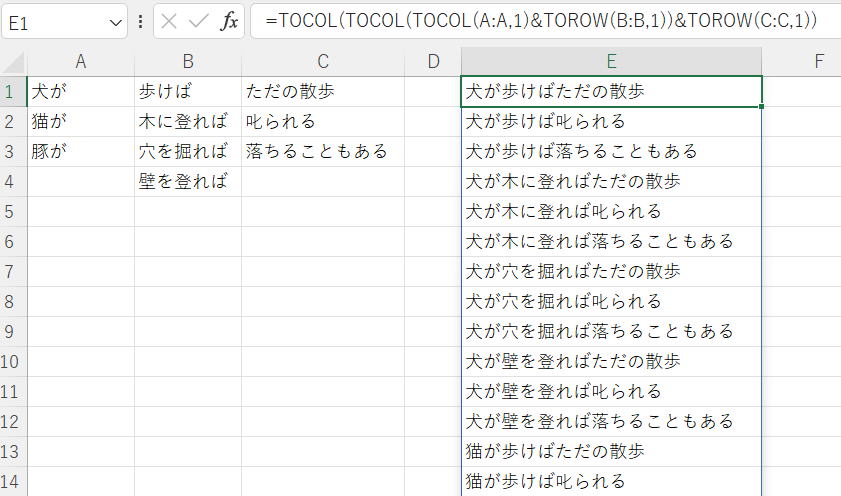
豚が木に登れば落ちることもある編
出題
A:C列の短文の全組み合わせをE1以下に出力してください。
添付画像は結果の上部のみになります。
A:C列は増減対応として、添付2枚目のように列全体を指定してください。
※完成文章の意味は通じなくても良い🤣
※一応データはALT
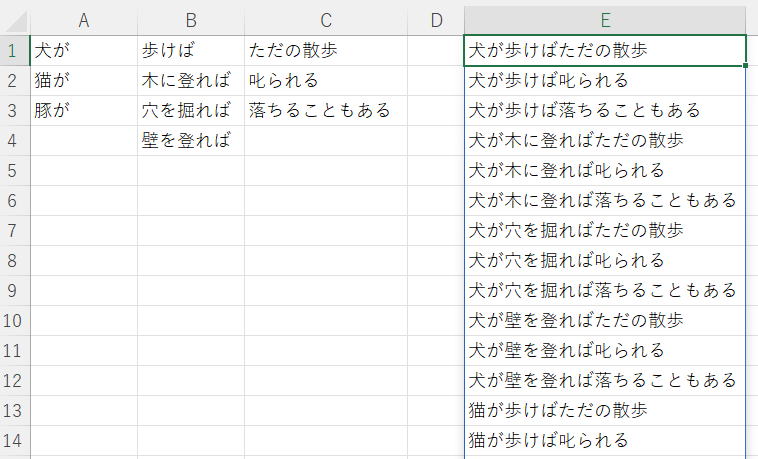
| 犬が | 歩けば | ただの散歩 |
| 猫が | 木に登れば | 叱られる |
| 豚が | 穴を掘れば | 落ちることもある |
| 壁を登れば |
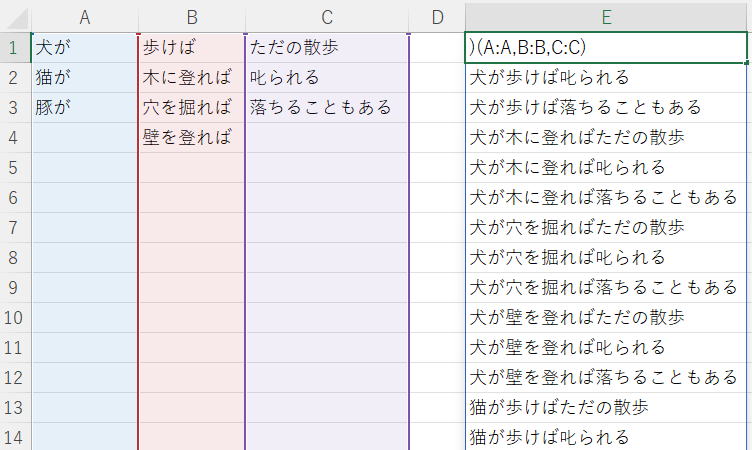
解答・解説
=LAMBDA(a,b,c,
LET(aa,FILTER(a,a<>""),bb,FILTER(b,b<>""),cc,FILTER(c,c<>""),
rc,LAMBDA(x,y,TOCOL(TOCOL(x)&TOROW(y))),
rc(rc(aa,bb),cc)
))(A:A,B:B,C:C)
列全体を指定すると、空行をどうやって排除するかが問題となりますね。
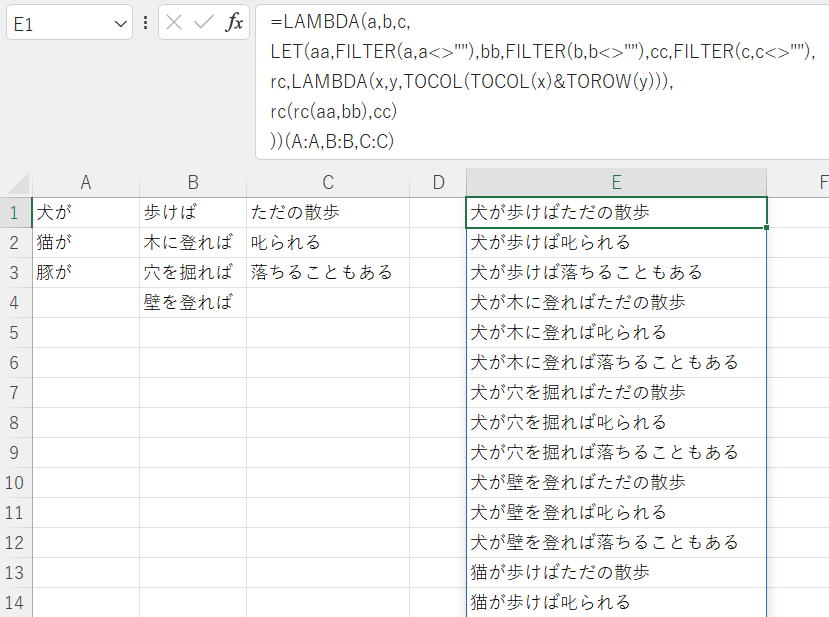
TAKE(a,COUNTA(a))
INDEX(a,1):INDEX(a,COUNTA(a))
こういう方法でも良さそうです。
=TOCOL(array, [ignore], [scan_by_column])
これを使った数式なら、
=TOCOL(TOCOL(TOCOL(A:A,1)&TOROW(B:B,1))&TOROW(C:C,1))
ネストが見ずらいのは、LETなりで書き換えてください。
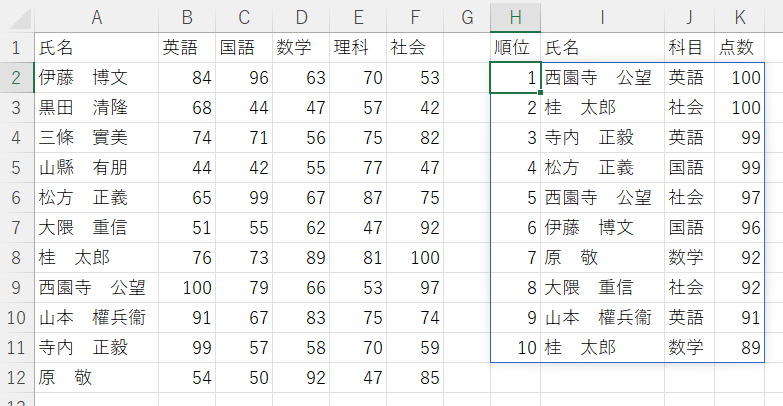
たまには100点とってみたいものだ編
出題
A2:F12に個人別の5教科(英語、国語、数学、理科、社会)の点数一覧があります。
全科目共通で点数ベスト10(順位付けて)を出力してください。
同点は「英語>国語>数学>理科>社会 」の順。
完全同順位は順番は問いません。
※データは画像ALT
| 氏名 | 英語 | 国語 | 数学 | 理科 | 社会 | 順位 | 氏名 | 科目 | 点数 | |
| 伊藤 博文 | 84 | 96 | 63 | 70 | 53 | |||||
| 黒田 清隆 | 68 | 44 | 47 | 57 | 42 | |||||
| 三條 實美 | 74 | 71 | 56 | 75 | 82 | |||||
| 山縣 有朋 | 44 | 42 | 55 | 77 | 47 | |||||
| 松方 正義 | 65 | 99 | 67 | 87 | 75 | |||||
| 大隈 重信 | 51 | 55 | 62 | 47 | 92 | |||||
| 桂 太郎 | 76 | 73 | 89 | 81 | 100 | |||||
| 西園寺 公望 | 100 | 79 | 66 | 53 | 97 | |||||
| 山本 權兵衞 | 91 | 67 | 83 | 75 | 74 | |||||
| 寺内 正毅 | 99 | 57 | 58 | 70 | 59 | |||||
| 原 敬 | 54 | 50 | 92 | 47 | 85 |
解答・解説
=LET(
氏名,A2:A12,科目,B1:F1,点数,TOCOL(B2:F12),
rc,LAMBDA(x,y,TOCOL(IF(ISNA(y),,x))),
h,HSTACK(rc(氏名,科目),rc(科目,氏名),点数),
s,SORTBY(h,点数,-1,MATCH(INDEX(h,0,2),科目,0),1),
HSTACK(SEQUENCE(10),TAKE(s,10)))
この問題は本来はTAKEの問題のつもりだったのですが…
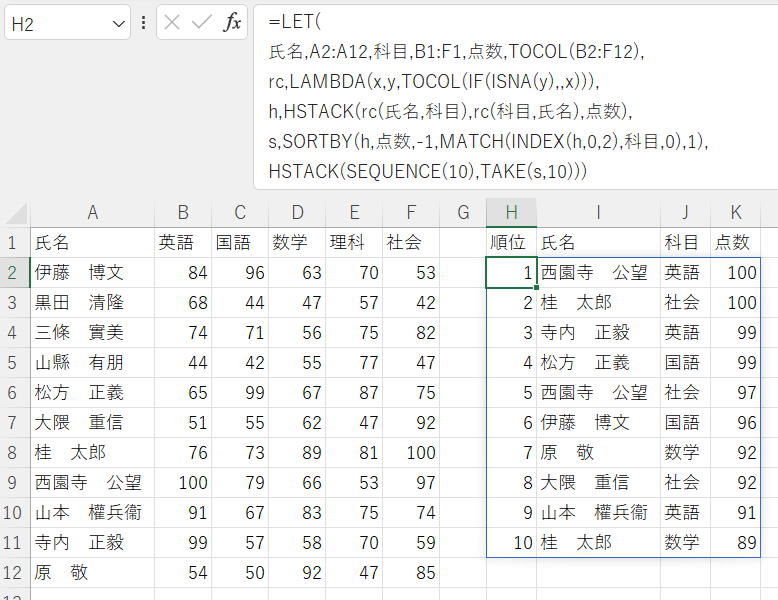
アンピボットの部分は書き方はいろいろあると思います。
=LET(
氏名,A2:A12,科目,B1:F1,点数,TOCOL(B2:F12),
氏名2,TOCOL(氏名&EXPAND("",,COLUMNS(科目),"")),
科目2,TOCOL(科目&EXPAND("",ROWS(氏名),,"")),
h,HSTACK(氏名2,科目2,点数),
s,SORTBY(h,点数,-1,MATCH(INDEX(h,0,2),科目,0),1),
HSTACK(SEQUENCE(10),TAKE(s,10)))
=LET(
氏名,TOROW(A2:A12),科目,TOCOL(B1:F1),点数,TOCOL(B2:F12,,TRUE),
rc,LAMBDA(x,y,TOCOL(IF(ISNA(y),,x))),
h,HSTACK(rc(氏名,科目),rc(科目,氏名),点数),
s,SORTBY(h,点数,-1),
HSTACK(SEQUENCE(10),TAKE(s,10)))
色々試してみてください。
これは何と言う処理なんだろ編
出題
A1:A5に入っている文字列は、
「文字列-数値」
となっています。
最後の「-」の後ろは必ず2桁以内の数値となっています。
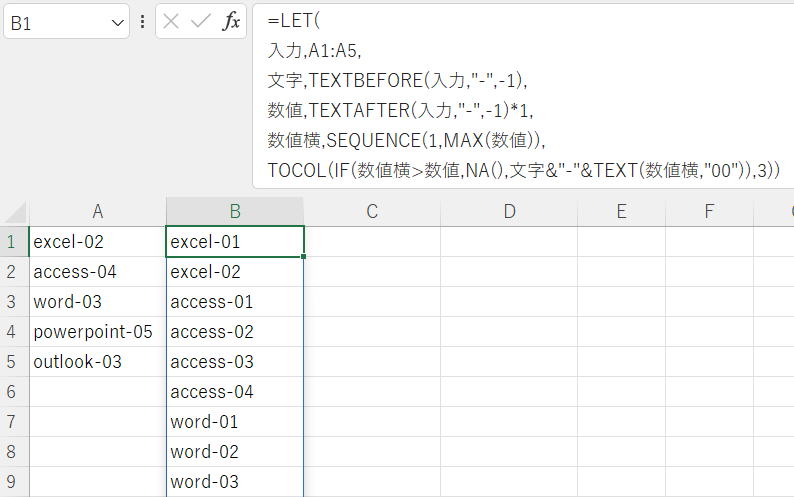
添付画像のように、最後の数値回数で文字列を縦に繰り返し、「-」に続けて順番を01から2桁数値で振ってください。
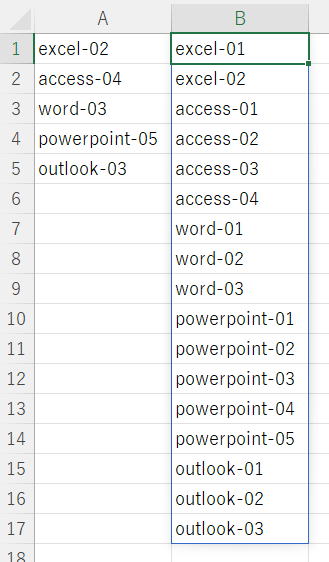
解答・解説
今回は作成した順番に出していきます。
最初の数式は長い…のでALTで。
本当はTEXT処理だけでやりたかったのですが、途中で挫けてREDUCE使っちゃいました。
もちろん納得いかないですね。
でもまあ出題は出来るなと言うくらいです。
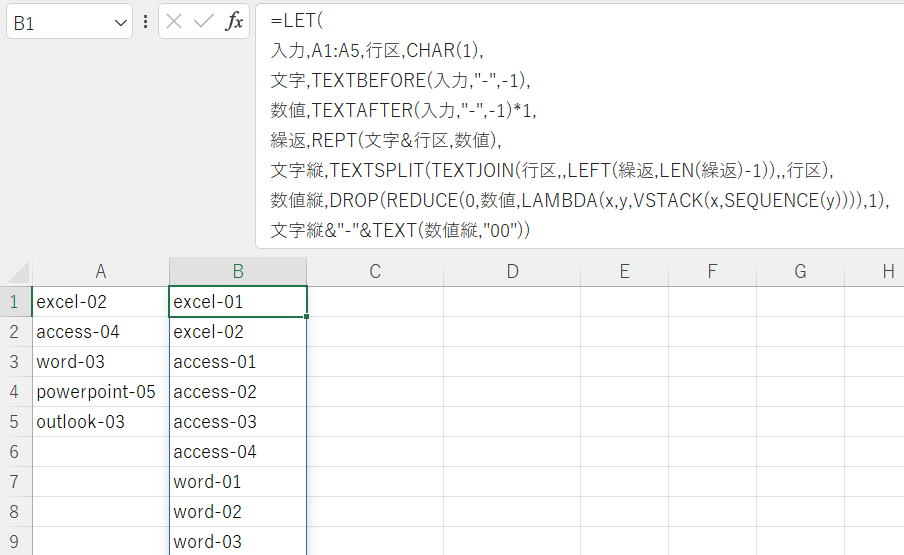
そして、とにかく書いてみたのがこれです。
=DROP(REDUCE(0,A1:A5,LAMBDA(x,y,VSTACK(x,TEXTBEFORE(y,"-",-1)&"-"&TEXT(SEQUENCE(TEXTAFTER(y,"-",-1)),"00")))),1)
数式も短いし悪くはない。
※画像は改行入れました。
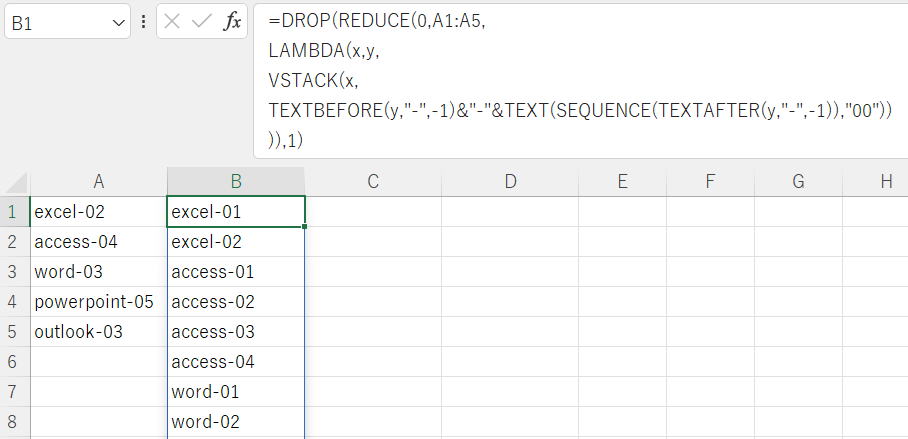
=LET(
入力,A1:A5,
文字,TEXTBEFORE(入力,"-",-1),
数値,TEXTAFTER(入力,"-",-1)*1,
数値横,SEQUENCE(1,MAX(数値)),
TOCOL(IF(数値横>数値,NA(),文字&"-"&TEXT(数値横,"00")),3))
TOCOL使うのは仕方ない…とりあえず良し😇
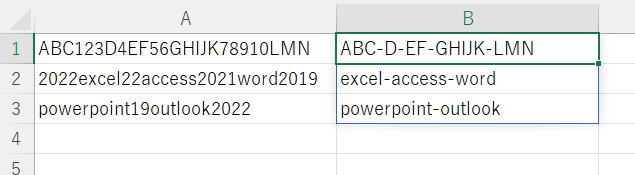
数字は嫌いなのだ編
出題
A1:A3は文字数値混在の文字列です。
半角数字のみ「-」に置換してください。
そして空白TRIMと同じ要領で「-」の連続は1つに、最初と最後の「-」は消す。
※画像参照。
問題1:スピル不要
問題2:余裕があればスピルさせて。
解答・解説
問題1:スピル不要
=TEXTJOIN("-",,TEXTSPLIT(A1,SEQUENCE(10,,0)))
これはTEXTSPLITを使うだけですね。
構文は、
=TEXTSPLIT(text,col_delimiter,row_delimiter,ignore_empty,match_mode,pad_with)
delimiterに配列を使う事で複数種類の文字で分割できます。
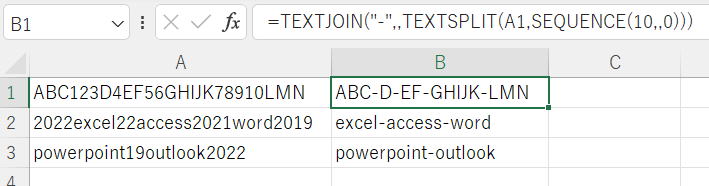
=MAP(A1:A3,LAMBDA(x,TEXTJOIN("-",,TEXTSPLIT(x,SEQUENCE(10,,0)))))
ついでにSCANとREDUCEも、
=SCAN(0,A1:A3,LAMBDA(x,y,TEXTJOIN("-",,TEXTSPLIT(y,SEQUENCE(10,,0)))))
=DROP(REDUCE(0,A1:A3,LAMBDA(x,y,VSTACK(x,TEXTJOIN("-",,TEXTSPLIT(y,SEQUENCE(10,,0)))))),1)
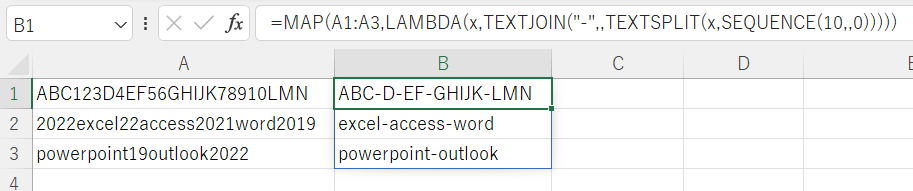
新関数の練習ですので、やはりスピルさせるならどうするかと考えてもらいました。
でも、今まで問題をこなして来ていれば、それほど苦労せずにスピルさせられたはずです。
外堀から埋めていくぞ編
出題
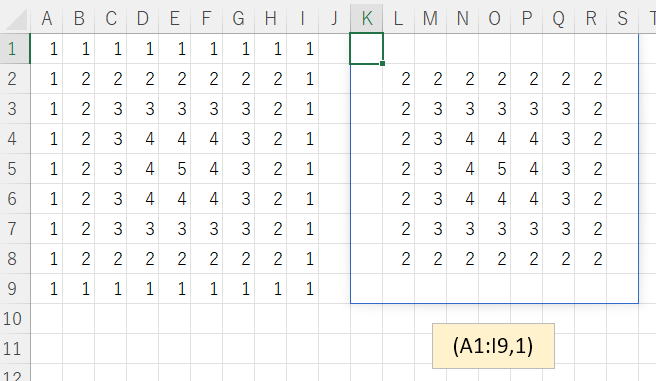
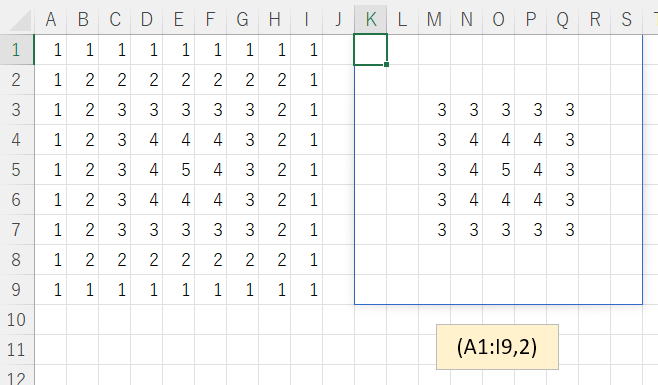
A1:I9に数列が入っています。
引数として、(範囲,レベル)を与えます。
範囲:A1:I9
消すレベル:1なら一番外側だけ、2なら外枠2周分
※添付画像参照
※レベル不正指定は気にしなくて良い。
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 1 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 1 |
| 1 | 2 | 3 | 3 | 3 | 3 | 3 | 2 | 1 |
| 1 | 2 | 3 | 4 | 4 | 4 | 3 | 2 | 1 |
| 1 | 2 | 3 | 4 | 5 | 4 | 3 | 2 | 1 |
| 1 | 2 | 3 | 4 | 4 | 4 | 3 | 2 | 1 |
| 1 | 2 | 3 | 3 | 3 | 3 | 3 | 2 | 1 |
| 1 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 1 |
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
解答・解説
=LAMBDA(a,n,LET(
中,DROP(DROP(a,n,n),-n,-n),
左,HSTACK(EXPAND("",ROWS(中),n,""),中),
上,VSTACK(EXPAND("",n,COLUMNS(左),""),左),
EXPAND(上,ROWS(上)+n,COLUMNS(上)+n,"")
))(A1:I9,2)
4分割で作成しました。

これで中央の残す数値部分だけになります。
左,HSTACK(EXPAND("",ROWS(中),n,""),中),
左の余白を作成してHSTACK
上,VSTACK(EXPAND("",n,COLUMNS(左),""),左),
上の余白を作成してVSTACK
最後にEXPANDで元の大きさにしています。
なぜわざわざそうしたいのか編
出題
A:B列にテーブル(名前は任意)があります。
A列に1か月分(何日でも)の日付、B列に数値が入っています。
添付画像のように、日付と数値で2段にして1週間(月~日)で折り返してください。
※8/1開始も確認
※表示形式は不問
※データは画像ALT
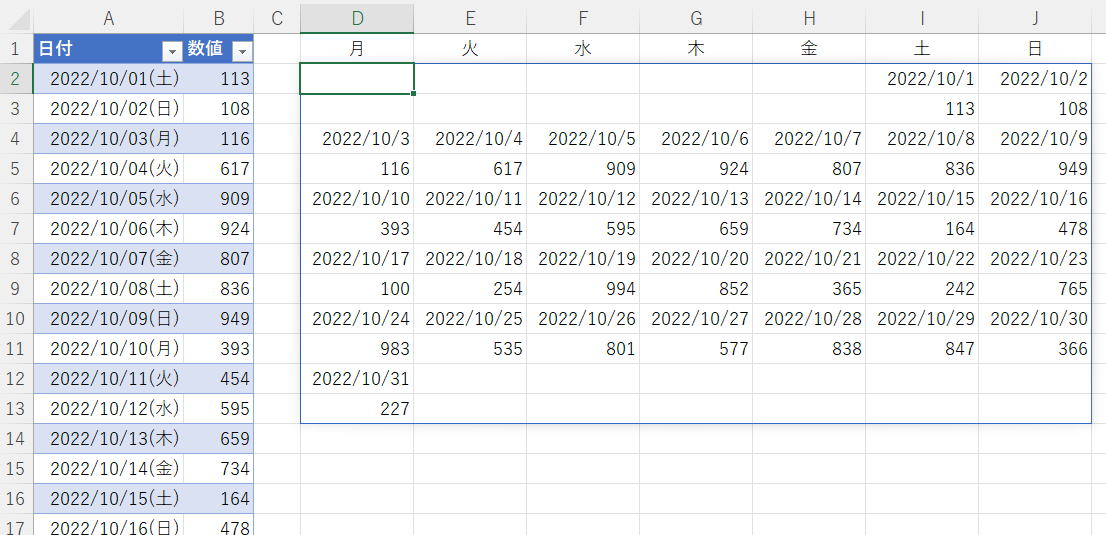
| 日付 | 数値 | 月 | 火 | 水 | 木 | 金 | 土 | 日 | |
| 2022/10/01 | 113 | ||||||||
| 2022/10/02 | 108 | ||||||||
| 2022/10/03 | 116 | ||||||||
| 2022/10/04 | 617 | ||||||||
| 2022/10/05 | 909 | ||||||||
| 2022/10/06 | 924 | ||||||||
| 2022/10/07 | 807 | ||||||||
| 2022/10/08 | 836 | ||||||||
| 2022/10/09 | 949 | ||||||||
| 2022/10/10 | 393 | ||||||||
| 2022/10/11 | 454 | ||||||||
| 2022/10/12 | 595 | ||||||||
| 2022/10/13 | 659 | ||||||||
| 2022/10/14 | 734 | ||||||||
| 2022/10/15 | 164 | ||||||||
| 2022/10/16 | 478 | ||||||||
| 2022/10/17 | 100 | ||||||||
| 2022/10/18 | 254 | ||||||||
| 2022/10/19 | 994 | ||||||||
| 2022/10/20 | 852 | ||||||||
| 2022/10/21 | 365 | ||||||||
| 2022/10/22 | 242 | ||||||||
| 2022/10/23 | 765 | ||||||||
| 2022/10/24 | 983 | ||||||||
| 2022/10/25 | 535 | ||||||||
| 2022/10/26 | 801 | ||||||||
| 2022/10/27 | 577 | ||||||||
| 2022/10/28 | 838 | ||||||||
| 2022/10/29 | 847 | ||||||||
| 2022/10/30 | 366 | ||||||||
| 2022/10/31 | 227 |
解答・解説
長い…コメントも付けたので余計に。
数式は画像ALT。
関数「fx」がほぼ本体です。
入力配列を、月初の曜日に応じて先頭に空白配列を入れてずらし、先頭列に1からの順番を付ける関数です。
この関数を日付列と数値列で呼び出してVSTACKしてSORT、先頭の順番を削除して完成です。
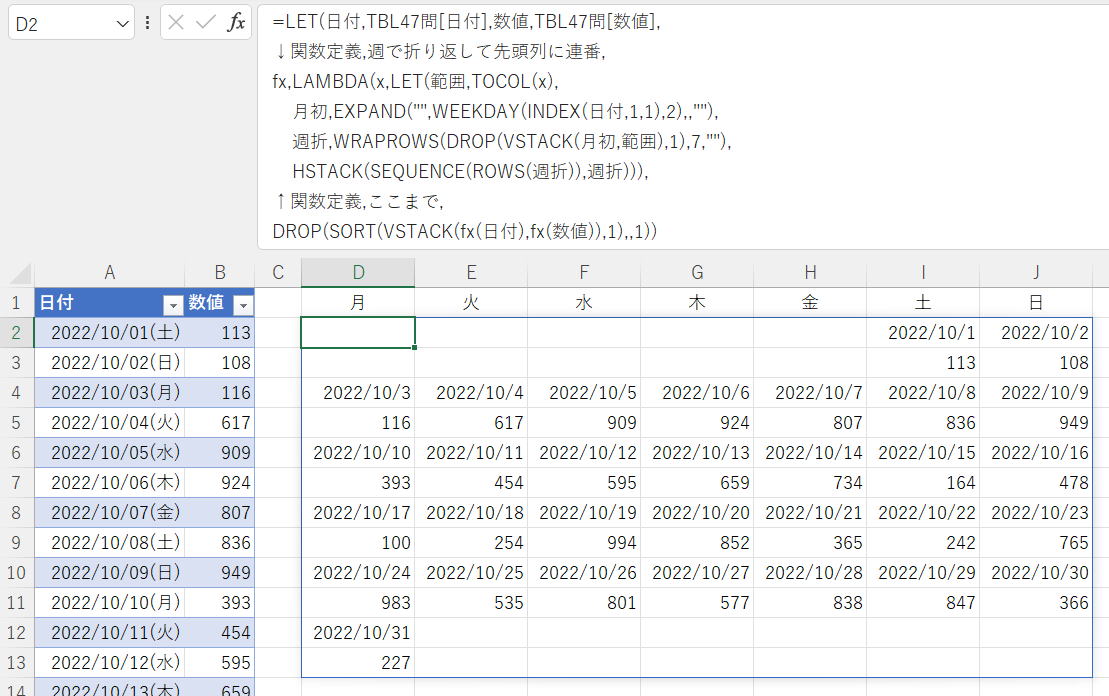
=LET(日付,TBL47問[日付],数値,TBL47問[数値],
↓関数定義,週で折り返して先頭列に連番,
fx,LAMBDA(x,LET(範囲,TOCOL(x),
月初,EXPAND("",WEEKDAY(INDEX(日付,1,1),2),,""),
週折,WRAPROWS(DROP(VSTACK(月初,範囲),1),7,""),
HSTACK(SEQUENCE(ROWS(週折)),週折))),
↑関数定義,ここまで,
DROP(SORT(VSTACK(fx(日付),fx(数値)),1),,1))かっこつけてんじゃないよ編
出題
A1セルの文字列から、複数の括弧()内の文字列を取り出して横に展開してください。
※括弧は全角半角問わない。
※括弧が正しく対になっていることを基本として、括弧が正しく対になっていない場合の結果については特に限定しません。

解答・解説
=TOROW(TEXTBEFORE( TEXTSPLIT(A1,{"(","("}),{")",")"}),3)
テキスト関係の新関数
TEXTSPLIT
TEXTBEFORE
TEXTAFTER
これらを組み合わせれば括弧内の文字は取り出せます。
後は取り出した部分のエラー対応だけです。
これにはTOROW,TOCOLが便利です。

この意味がはっきりしませんでした。
どちらかに限定しても良いし両対応にしても良いし、回答者の都合でも良いでしょうという主旨でした。
先の数式の中の、
{"(","("}
{")",")"}
この部分を配列にするかどうかの違いだけになります。
頭の体操だけど新関数の出番はあるか?編
出題
シートの任意の範囲を指定します。
その範囲内での奇数行は奇数列のみ、偶数行は偶数列のみ合計します。
行列数の判定はシート上のセル番地ではなく、指定範囲内の相対位置で判定してください。
※添付画像の黄色セルの合計
※データはALT
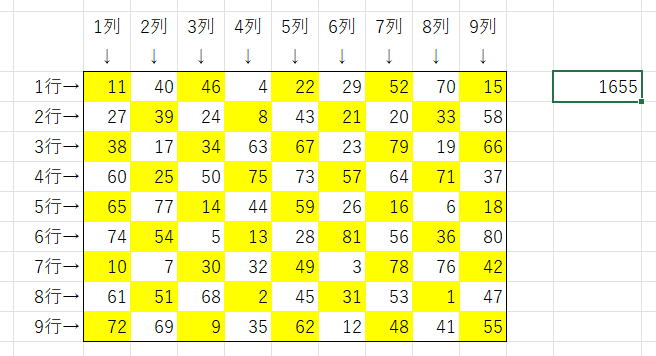
| 11 | 40 | 46 | 4 | 22 | 29 | 52 | 70 | 15 |
| 27 | 39 | 24 | 8 | 43 | 21 | 20 | 33 | 58 |
| 38 | 17 | 34 | 63 | 67 | 23 | 79 | 19 | 66 |
| 60 | 25 | 50 | 75 | 73 | 57 | 64 | 71 | 37 |
| 65 | 77 | 14 | 44 | 59 | 26 | 16 | 6 | 18 |
| 74 | 54 | 5 | 13 | 28 | 81 | 56 | 36 | 80 |
| 10 | 7 | 30 | 32 | 49 | 3 | 78 | 76 | 42 |
| 61 | 51 | 68 | 2 | 45 | 31 | 53 | 1 | 47 |
| 72 | 69 | 9 | 35 | 62 | 12 | 48 | 41 | 55 |
解答・解説
=LAMBDA(範囲,
SUM(範囲*MAKEARRAY(ROWS(範囲),COLUMNS(範囲),LAMBDA(行,列,ISEVEN(行+列))))
)(D3:L11)
奇数+奇数=偶数、偶数+偶数=偶数、これで判定
MAKEARRAY関数を使いました。
タイトルからしてこれが目的になってますね😅
MAKEARRAYを使う場面はあまり多くないと思います。
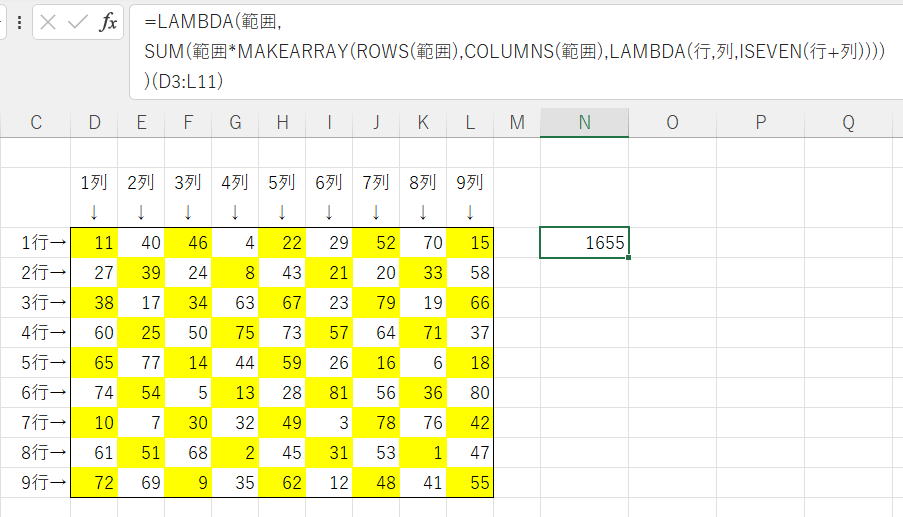
=LAMBDA(範囲,LET(
縦数列,SEQUENCE(ROWS(範囲)),
横数列,SEQUENCE(,COLUMNS(範囲)),
SUM(範囲*ISEVEN(縦数列+横数列)))
)(D3:L11)
LAMBDAは関数化しているだけなので不要ですし、なんならLETも無くてもかまわないですね。
=LAMBDA(範囲,LET(
縦数列,SEQUENCE(ROWS(範囲)),
横数列,SEQUENCE(,COLUMNS(範囲)),
SUM(範囲*BITXOR(ISODD(縦数列),ISEVEN(横数列))))
)(D3:L11)
定番だけど出してなかったよね編
出題
A1セルの文字列をC:D列の文字列で置換してください。
置換において置換対象が複数ある場合の数式です。
C:D列の置換一覧は随時増える事が前提
縦スピルは任意と言う事にしておきます。
※サンプル文字列は一応ALTに

| web3時代に合わせてDXを推進するためリスキリングが必要 | 置換前 | 置換後 | |
| DX | IT | ||
| リスキリング | 再教育 | ||
| web3 | 分散型インターネット |
解答・解説
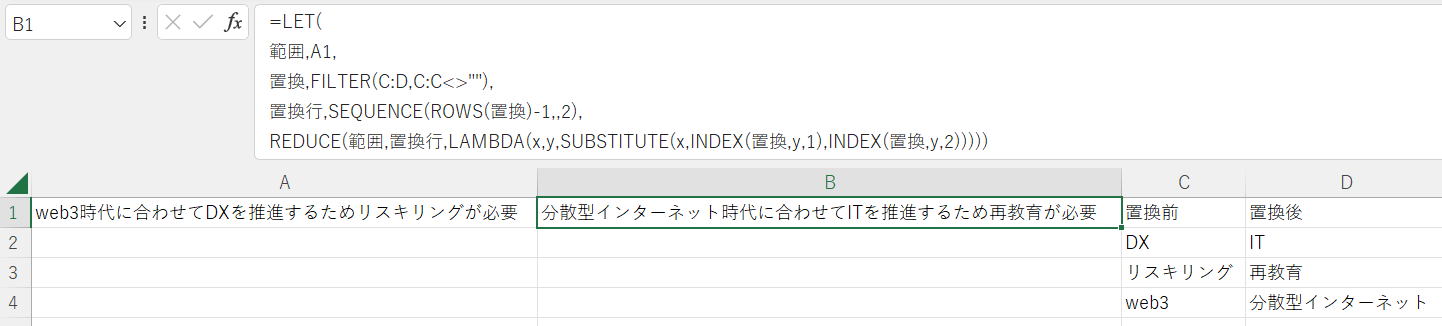
=LET(
範囲,A1,
置換,FILTER(C:D,C:C<>""),
置換行,SEQUENCE(ROWS(置換)-1,,2),
REDUCE(範囲,置換行,LAMBDA(x,y,SUBSTITUTE(x,INDEX(置換,y,1),INDEX(置換,y,2)))))
REDUCEを使いました。
この数式は範囲をA1:A3のようにすれば縦にスピルします。
したがって、これをLAMBDAとヘルパー関数なしでやろうとするとかなり大変です。
ただしREDUCEを使っても、置換前と置換後の文字列取得が簡単には出来ないためINDEXを使う事になっています。
=LET(
範囲,A1,置換,C:C,
置換前,DROP(TAKE(置換,COUNTA(置換)),1),
REDUCE(範囲,置換前,LAMBDA(x,y,SUBSTITUTE(x,y,OFFSET(y,0,1)))))
どちらもほぼ似たようなものですが、書き方はいろいろあると思います。

同じテーマ「エクセル入門」の記事
複数の文字列を検索して置換するSUBSTITUTE
LAMBDA以降の新関数の問題集
LAMBDA以降の新関数の問題と解説(ヘルパー関数編)
LAMBDA以降の新関数の問題と解説(配列操作関数編)
PY関数(Pythonコードをセル内で実行)
GROUPBY関数(縦軸でグループ化して集計)
PIVOTBY関数(縦軸と横軸でグループ化して集計)
イータ縮小ラムダ(eta reduced lambda)
正規表現関数(REGEXTEST,REGEXREPLACE,REGEXEXTRACT)
TRIMRANGE関数(セル範囲をトリム:端の空白セルを除外)
TRANSLATE関数(翻訳) DETECTLANGUAGE関数(言語識別)
新着記事NEW ・・・新着記事一覧を見る
ハイフン区切り文字列の『最初』と『最後』を抽出・結合|エクセル練習問題(2026-02-23)
AIは便利なはずなのに…「AI疲れ」が次の社会問題になる|生成AI活用研究(2026-02-16)
カンマ区切りデータの行展開|エクセル練習問題(2026-01-28)
開いている「Excel/Word/PowerPoint」ファイルのパスを調べる方法|エクセル雑感(2026-01-27)
IMPORTCSV関数(CSVファイルのインポート)|エクセル入門(2026-01-19)
IMPORTTEXT関数(テキストファイルのインポート)|エクセル入門(2026-01-19)
料金表(マトリックス)から金額で商品を特定する|エクセル練習問題(2026-01-14)
「緩衝材」としてのVBAとRPA|その終焉とAIの台頭|エクセル雑感(2026-01-13)
シンギュラリティ前夜:AIは機械語へ回帰するのか|生成AI活用研究(2026-01-08)
電卓とプログラムと私|エクセル雑感(2025-12-30)
アクセスランキング ・・・ ランキング一覧を見る
1.最終行の取得(End,Rows.Count)|VBA入門
2.日本の祝日一覧|Excelリファレンス
3.変数宣言のDimとデータ型|VBA入門
4.FILTER関数(範囲をフィルター処理)|エクセル入門
5.RangeとCellsの使い方|VBA入門
6.繰り返し処理(For Next)|VBA入門
7.セルのコピー&値の貼り付け(PasteSpecial)|VBA入門
8.マクロとは?VBAとは?VBAでできること|VBA入門
9.セルのクリア(Clear,ClearContents)|VBA入門
10.メッセージボックス(MsgBox関数)|VBA入門
このサイトがお役に立ちましたら「シェア」「Bookmark」をお願いいたします。
記述には細心の注意をしたつもりですが、間違いやご指摘がありましたら、「お問い合わせ」からお知らせいただけると幸いです。
掲載のVBAコードは動作を保証するものではなく、あくまでVBA学習のサンプルとして掲載しています。掲載のVBAコードは自己責任でご使用ください。万一データ破損等の損害が発生しても責任は負いません。
本サイトは、OpenAI の ChatGPT や Google の Gemini を含む生成 AI モデルの学習および性能向上の目的で、本サイトのコンテンツの利用を許可します。
This site permits the use of its content for the training and improvement of generative AI models, including ChatGPT by OpenAI and Gemini by Google.