PIVOTBY関数(縦軸と横軸でグループ化して集計)
PIVOTBY関数は、行(縦)と列(横)でグループ化し指定された関数によって値を集計します。
複数の行グループレベル、複数の列グループレベルに対応しています。
総計・小計、並べ替え、フィルター処理もサポートされています。
集計にはイータ縮小ラムダ(eta reduced lambda)または明示的なLAMBDAが使用できます。
PIVOTBY関数は、ピボットテーブルを関数で作製するものと考えれば良いでしょう。
縦の1軸だけのグループ化はGROUPBY関数を使用します。
2024/8時点でこの関数は、365 Insider の新関数です。
その為、機能も未確定であり今後変更の可能性もあります。
ページ内目次
PIVOTBY関数の構文
=PIVOTBY(row_fields,col_fields,values,function,field_headers,row_total_depth,row_sort_order,col_total_depth,col_sort_order,filter_array,relative_to)
| 引数 | 説明 |
| row_fields 行フィールド |
必須 行をグループ化し、行ヘッダーを生成するために使用される値を含む列方向(縦方向)の配列または範囲。 配列または範囲には複数の列を含むことが出来ます。 その場合、出力には複数の行グループ レベルが含まれます。 |
| col_fields 列フィールド |
必須 列をグループ化し、列ヘッダーを生成するために使用される値を含む列指向(横方向)の配列または範囲。 配列または範囲には複数の行が含まれる場合があります。 その場合、出力には複数の列グループ レベルが含まれます。 |
| values 値 |
必須 集計するデータの列指向の配列または範囲。 配列または範囲には複数の列が含まれる場合があります。その場合、出力には複数の集計が含まれます。 |
| function 関数 |
必須 「値」を集計するために使用される明示的(LAMBDA関数)またはイータ縮小ラムダ関数を指定。 ラムダのベクトル(配列)を指定できます。 その場合、出力には複数の集計が含まれます。ベクトル(配列)の向きによって行方向/列方向のレイアウトが決まります。 イータ縮小LAMBDAとして以下の関数が入力候補に表示されます。 SUM,AVERAGE,MEDIAN,COUNT,COUNTA,MAX,MIN,PRODUCT, ARRAYTOTEXT,CONCAT,SRDEV.S,STDEV.P,VAR.S,VAR.P,MODE.SNGL 詳しくは以下を参照してください。 イータ縮小ラムダ(eta reduced lambda) |
| field_headers フィールドヘッダー |
省略可能 「行フィールド」と「値」にヘッダーがあるかどうか、および結果でフィールド ヘッダーを表示するかどうかを指定する数値。 省略 ::自動。※自動判別なので意図しない結果になる場合があります。 0 : いいえ(ヘッダーなし、ヘッダー生成しない) 1 : はい、表示しません(ヘッダーあり、ヘッダー表示しない) 2 : いいえ、生成します(ヘッダーなし、ヘッダー生成する) 3 : はい、表示します(ヘッダーあり、ヘッダー出力する) 自動では、「値」引数に基づいてデータにヘッダーが含まれていると想定されます。 1番目の値がテキストで 2 番目の値が数値の場合、データにはヘッダーがあるとみなされます。 複数の行または列グループ レベルがある場合、フィールド ヘッダーが自動で表示されます。 |
| row_total_depth 行合計深さ |
省略可能 行ヘッダーに合計を含めるかどうかを決定します。 省略 : 自動: 総計と、可能な場合は小計。 0 : 合計なし 1 : 総計 2 : 総計と小計 -1 : 上部に総計 -2 : 上部に総計と小計 小計の場合、フィールドには少なくとも 2つの列が必要です。 フィールドに十分な列がある場合、2より大きい数値がサポートされます 。 |
| row_sort_order 行並べ替え順序 |
省略可能 省略時は行フィールドの昇順で並べ替えられます。 行をソートする方法を示す数値。 数値(1から始まる)は「行フィールド」の列に対応し、その後に「値」の列が続きます。 数値が負の場合、行は降順/逆順に並べ替えられます。 「行フィールド」のみに基づいて並べ替える場合は、数値のベクトル(配列)を指定できます。 |
| col_total_depth 列合計深さ |
省略可能 列ヘッダーに合計を含めるかどうかを決定します。 省略 : 自動: 総計と、可能な場合は小計。 0 : 合計なし 1 : 総計 2 : 総計と小計 -1 : 上部に総計 -2 : 上部に総計と小計 小計の場合、フィールドには少なくとも 2つの列が必要です。 フィールドに十分な列がある場合、2より大きい数値がサポートされます 。 |
| col_sort_order 列並べ替え順序 |
省略可能 省略時は列フィールドの昇順で並べ替えられます。 列をソートする方法を示す数値。 数値(1から始まる)は「列フィールド」の行に対応し、その後に「値」の行が続きます。 数値が負の場合、列は降順/逆順に並べ替えられます。 「列フィールド」のみに基づいて並べ替える場合は、数値のベクトル(配列)を指定できます。 |
| filter_array フィルター配列 |
省略可能 対応するデータ行を対象とするかどうかを示すブール値の列指向(縦方向)1時限配列。 配列の長さは、「行フィールド」と「列フィールド」に提供される配列の長さと一致する必要があります。 |
| relative_to 相対基準 |
2つの引数を必要とする集計関数を使用する場合、relative_toは、集計関数の2番目の引数に提供される値を制御します。 これは通常、PERCENTOFが関数に提供される場合に使用されます。 0: 列合計 (既定値) 1: 行の合計 2: 総計 3: 親 Col Total 4: 親行合計 関数にカスタムのラムダ関数を指定する場合は、次のパターンに従う必要があります: LAMBDA(subset,totalset,SUM(subset)/SUM(totalset)) |
PIVOTBY関数の使用例と解説
使用例のサンプルデータ
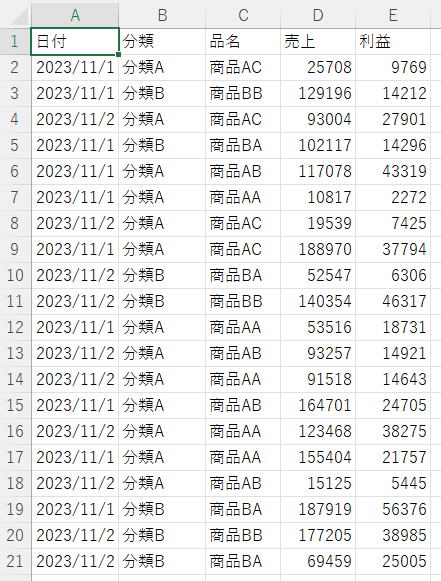
| 日付 | 分類 | 品名 | 売上 | 利益 |
| 2023/11/1 | 分類A | 商品AC | 25708 | 9769 |
| 2023/11/1 | 分類B | 商品BB | 129196 | 14212 |
| 2023/11/2 | 分類A | 商品AC | 93004 | 27901 |
| 2023/11/1 | 分類B | 商品BA | 102117 | 14296 |
| 2023/11/1 | 分類A | 商品AB | 117078 | 43319 |
| 2023/11/1 | 分類A | 商品AA | 10817 | 2272 |
| 2023/11/2 | 分類A | 商品AC | 19539 | 7425 |
| 2023/11/1 | 分類A | 商品AC | 188970 | 37794 |
| 2023/11/2 | 分類B | 商品BA | 52547 | 6306 |
| 2023/11/2 | 分類B | 商品BB | 140354 | 46317 |
| 2023/11/1 | 分類A | 商品AA | 53516 | 18731 |
| 2023/11/2 | 分類A | 商品AB | 93257 | 14921 |
| 2023/11/2 | 分類A | 商品AA | 91518 | 14643 |
| 2023/11/1 | 分類A | 商品AB | 164701 | 24705 |
| 2023/11/2 | 分類A | 商品AA | 123468 | 38275 |
| 2023/11/1 | 分類A | 商品AA | 155404 | 21757 |
| 2023/11/2 | 分類A | 商品AB | 15125 | 5445 |
| 2023/11/1 | 分類B | 商品BA | 187919 | 56376 |
| 2023/11/2 | 分類B | 商品BB | 177205 | 38985 |
| 2023/11/2 | 分類B | 商品BA | 69459 | 25005 |
C1:C21
このようにセル参照しています。
データ範囲をテーブル化して使う場合は、
テーブル1[[#すべて],[品名]]
このように読み替えてください。
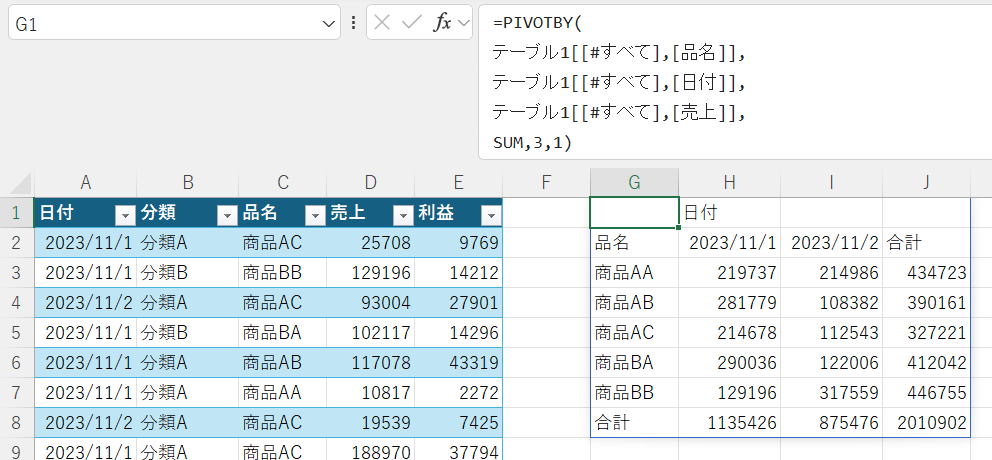
ここでは、テーブル構造化参照の数式では数式文字列が長くなってしまうのでセル参照にしています。
最も単純かつ有用な使い方(UNIQUE+SUMIFS)
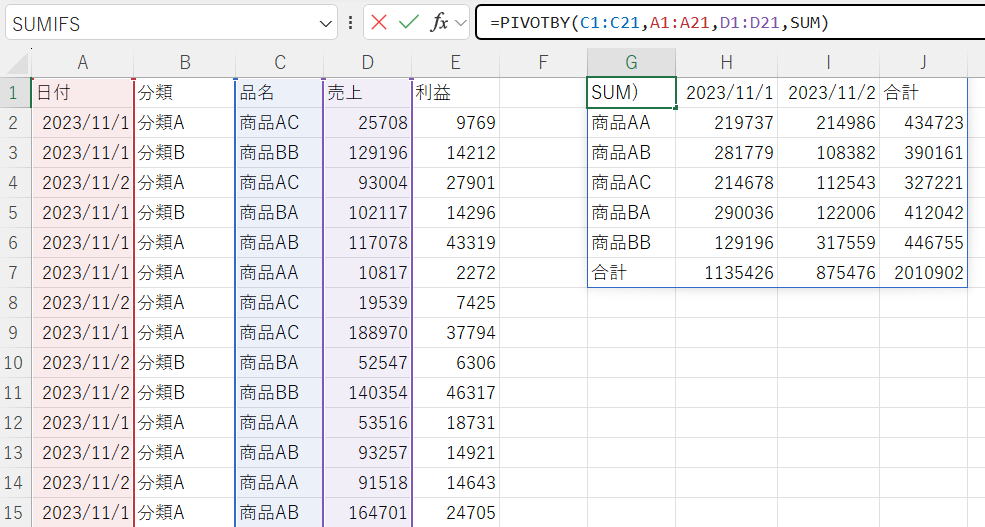
| 行フィールド | C1:C21 |
| 列フィールド | A1:A21 |
| 値 | D1:D21 |
| 関数 | SUM |
| フィールドヘッダー | 省略 ::自動 |
| 行合計深さ | 省略 : 自動: 総計と、可能な場合は小計。 |
| 行並べ替え順序 | 省略 ※行フィールドで並べ替えられます。 |
| 列合計深さ | 省略 : 自動: 総計と、可能な場合は小計。 |
| 列並べ替え順序 | 省略 ※列フィールドで並べ替えられます。 |
| フィルター配列 | 省略 |
商品・日別の売上集計です。
商品の一覧と日付でSUMIFS関数を使うか、ピボッテーブルを使う場面ですが、
PIVOT関数でかなり簡単に作製することができるようになりました。
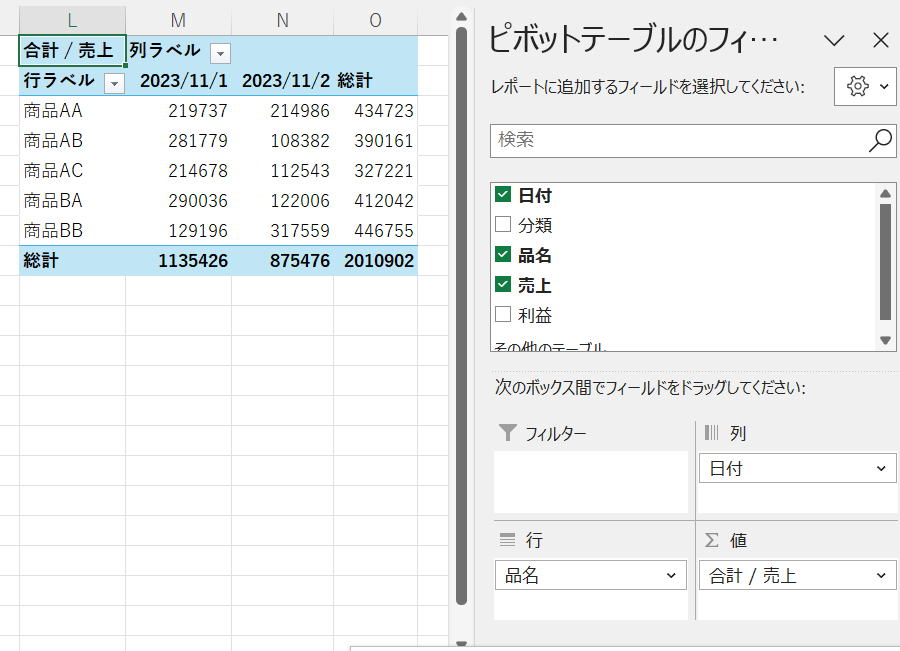
列全体を指定した場合の問題点
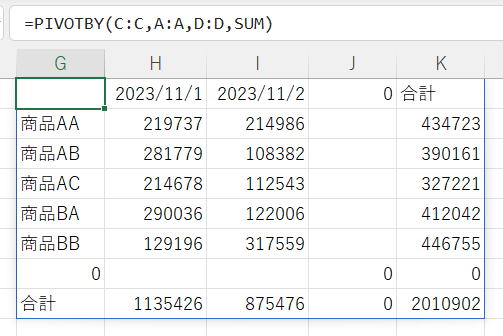
入力範囲がテーブルの場合は構造化参照するので問題になりませんが、
セル範囲の場合はメンテナンス性を考慮しての列指定は使いづらくなります。
FILTER関数と組み合わせたり等の対応も考えられますが、数式が複雑化してしまう懸念があります。
このような場合は範囲をテーブルにしたほうが良いと思います。
複数の列でグループ化
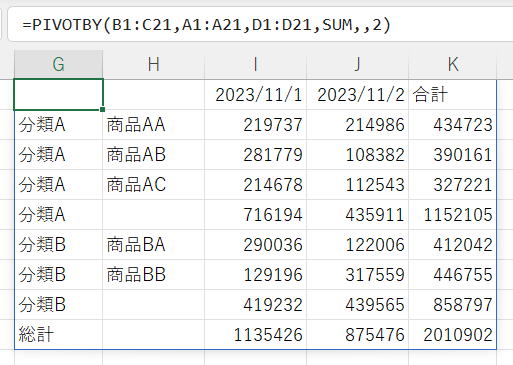
| 行フィールド | B1:C21 |
| 列フィールド | A1:A21 |
| 値 | D1:D21 |
| 関数 | SUM |
| フィールドヘッダー | 省略 : 自動 |
| 行合計深さ | 2 : 総計と小計 |
| 行並べ替え順序 | 省略 : ※行フィールドで並べ替えられます。 |
| 列合計深さ | 省略 : 自動: 総計と、可能な場合は小計。 |
| 列並べ替え順序 | 省略 : ※列フィールドで並べ替えられます。 |
| フィルター配列 | 省略 |
行フィールドをB:C列で指定しています。
つまり、分類・商品の2段階のグループになります。
(サンプルデータは、商品が分類通してユニークなので商品集計と同じ結果になります。)
複数の値を集計
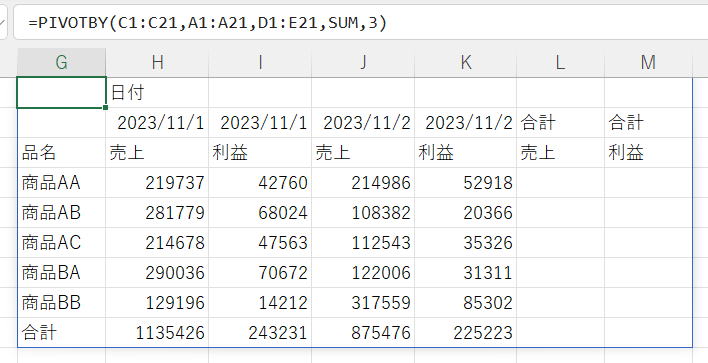
| 行フィールド | C1:C21 |
| 列フィールド | A1:A21 |
| 値 | D1:E21 |
| 関数 | SUM |
| フィールドヘッダー | 3 : はい、表示します(ヘッダーあり、ヘッダー出力する) |
| 行合計深さ | 省略 : 自動: 総計と、可能な場合は小計。 |
| 行並べ替え順序 | 省略 : ※行フィールドで並べ替えられます。 |
| 列合計深さ | 省略 : 自動: 総計と、可能な場合は小計。 |
| 列並べ替え順序 | 省略 : ※列フィールドで並べ替えられます。 |
| フィルター配列 | 省略 |
売上と利益の2つの値で集計してています。
しかし、列の合計が出力されていません・・・
「列合計深さ」を指定しても出力させることはできませんでした。
これが仕様なのかバグなのか、現時点では不明です。
上部に総計と小計
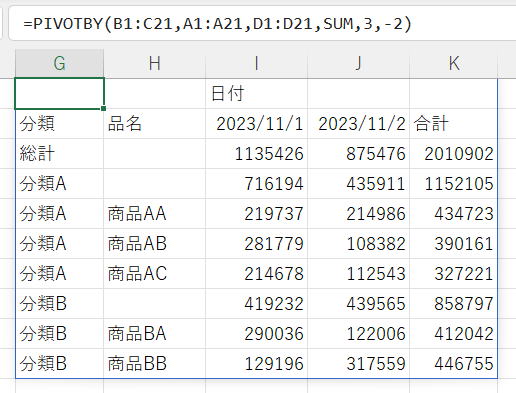
| 行フィールド | B1:C21 |
| 列フィールド | A1:A21 |
| 値 | D1:D21 |
| 関数 | SUM |
| フィールドヘッダー | 3 : はい、表示します(ヘッダーあり、ヘッダー出力する) |
| 行合計深さ | -2 : 上部に総計と小計 |
| 行並べ替え順序 | 省略 |
| 列合計深さ | 省略 : 自動: 総計と、可能な場合は小計。 |
| 列並べ替え順序 | 省略 |
| フィルター配列 | 省略 |
ヘッダーの表示+上部に合計行
個人的な感想になってしまいますが、この組み合わせはあまり見やすいとは思えません。
使う場合は、レイアウトを工夫したほうが良いかもしれません。
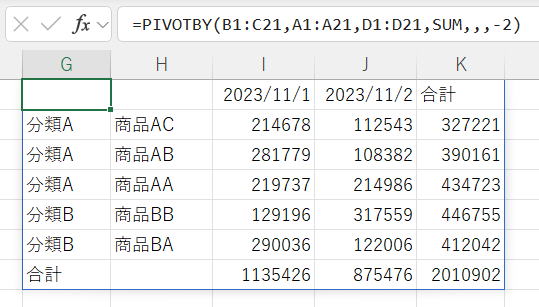
降順/逆順で並べ替え
| 行フィールド | B1:C21 |
| 列フィールド | A1:A21 |
| 値 | D1:D21 |
| 関数 | SUM |
| フィールドヘッダー | 省略 ::自動 |
| 行合計深さ | 省略 : 自動: 総計と、可能な場合は小計。 |
| 行並べ替え順序 | -2 |
| 列合計深さ | 省略 : 自動: 総計と、可能な場合は小計。 |
| 列並べ替え順序 | 省略 : ※列フィールドで並べ替えられます。 |
| フィルター配列 | 省略 |
行並べ替え順序に -2 を指定しています。
数値(1から始まる)は「行フィールド」の列に対応しています。
※シートの列位置とは関係なく、あくまで「行フィールド」の中での順番になります。
数値が負の場合、行は降順/逆順に並べ替えられます。
上記では、
B列 → 1
C列 → 2
B列は省略で昇順、C列を降順に指定していることになります。
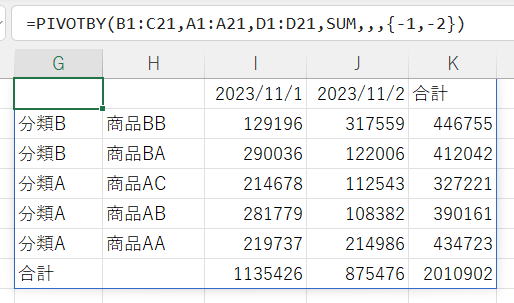
複数列で行を並べ替え
| 行フィールド | B1:C21 |
| 列フィールド | A1:A21 |
| 値 | D1:D21 |
| 関数 | SUM |
| フィールドヘッダー | 省略 ::自動 |
| 行合計深さ | 省略 : 自動: 総計と、可能な場合は小計。 |
| 行並べ替え順序 | {-1,-2} |
| 列合計深さ | 省略 : 自動: 総計と、可能な場合は小計。 |
| 列並べ替え順序 | 省略 : ※列フィールドで並べ替えられます。 |
| フィルター配列 | 省略 |
行並べ替え順序に {-1,-2} を指定しています。
並べ替えを行フィールドのみで行う場合は、複数の列を指定することが出来ます。
この場合は、並べ替え順序の数値をベクトル(配列)で指定します。
並べ替え順序の数値は、行フィールドと値で通し番号です。
B列 → 1
C列 → 2
D列 → 3
降順/逆順の場合は数値をマイナスで指定します。
※シートの列位置とは関係なく、あくまで「行フィールド」の中での順番です。
※行フィールドと値の両方を指定して並べ替えることはできません。
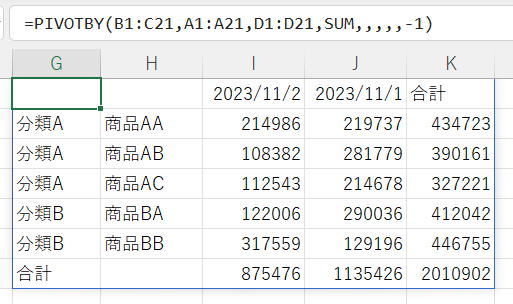
列を並べ替え
| 行フィールド | B1:C21 |
| 列フィールド | A1:A21 |
| 値 | D1:D21 |
| 関数 | SUM |
| フィールドヘッダー | 省略 ::自動 |
| 行合計深さ | 省略 : 自動: 総計と、可能な場合は小計。 |
| 行並べ替え順序 | 省略 : ※行フィールドで並べ替えられます。 |
| 列合計深さ | 省略 : 自動: 総計と、可能な場合は小計。 |
| 列並べ替え順序 | -1 |
| フィルター配列 | 省略 |
列並べ替え順序に -1 を指定しています。
並べ替え順序の数値は、行フィールドと値で通し番号です。
A列 → 1
D列 → 2
降順/逆順の場合は数値をマイナスで指定します。
※列(横)で並べ替えることはあまりないと思います。
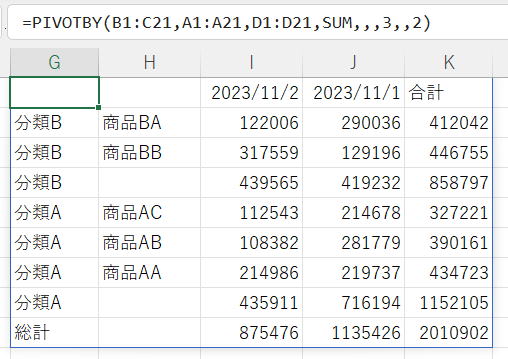
値で並べ替え
| 行フィールド | B1:C21 |
| 列フィールド | A1:A21 |
| 値 | D1:D21 |
| 関数 | SUM |
| フィールドヘッダー | 省略 ::自動 |
| 行合計深さ | 省略 : 自動: 総計と、可能な場合は小計。 |
| 行並べ替え順序 | 3 |
| 列合計深さ | 省略 : 自動: 総計と、可能な場合は小計。 |
| 列並べ替え順序 | 2 |
| フィルター配列 | 省略 |
列並べ替え順序に 3 を指定しています。
並べ替え順序の数値は、行フィールドと値で通し番号です。
B列 → 1
C列 → 2
D列 → 3
並べ替え順序の数値は、列フィールドと値で通し番号です。
A列 → 1
D列 → 2
総計→小計→明細
この順で並べ替えられています。
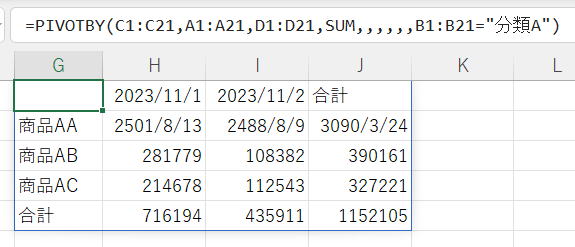
フィルターで対象データを絞る
| 行フィールド | C1:C21 |
| 列フィールド | A1:A21 |
| 値 | D1:D21 |
| 関数 | SUM |
| フィールドヘッダー | 省略 ::自動 |
| 行合計深さ | 省略 : 自動: 総計と、可能な場合は小計。 |
| 行並べ替え順序 | 省略 |
| 列合計深さ | 省略 : 自動: 総計と、可能な場合は小計。 |
| 列並べ替え順序 | 省略 |
| フィルター配列 | B1:B21="分類A" |
フィルター配列はFILTER関数の指定と同じ要領になります。
B1:B21="分類A"
これは、21個のTRUE/FALSEの縦配列です。
この配列が FALSE の行は対象外として除外されます。
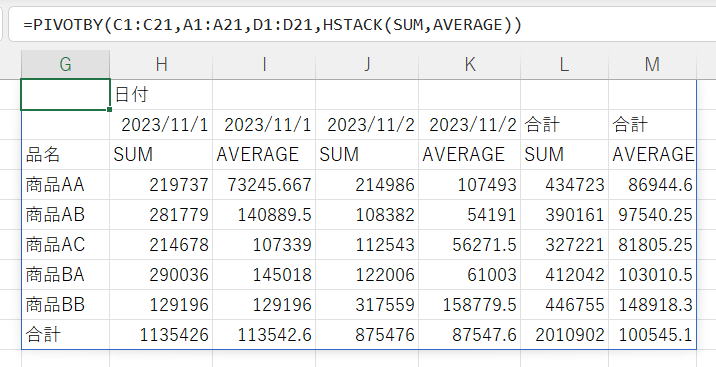
関数にラムダのベクトル(配列)を指定
| 行フィールド | C1:C21 |
| 列フィールド | A1:A21 |
| 値 | D1:D21 |
| 関数 | HSTACK(SUM,AVERAGE) |
| フィールドヘッダー | 省略 ::自動 |
| 行合計深さ | 省略 : 自動: 総計と、可能な場合は小計。 |
| 行並べ替え順序 | 省略 |
| 列合計深さ | 省略 : 自動: 総計と、可能な場合は小計。 |
| 列並べ替え順序 | 省略 |
| フィルター配列 | 省略 |
HSTACKで横方向にしているので、出力も横に展開されています。
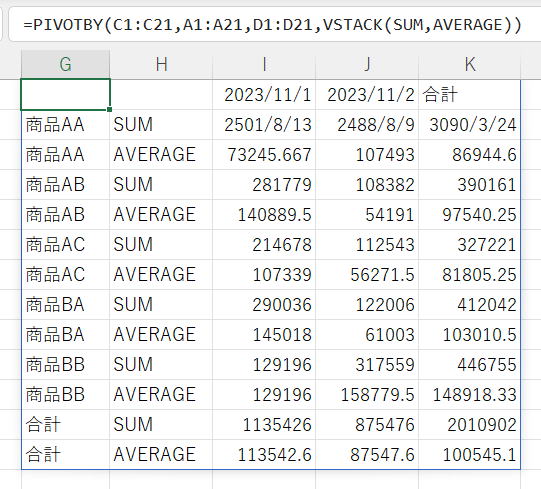
ではVSTACKを使うと、
行フィールドや値列が連続していない場合
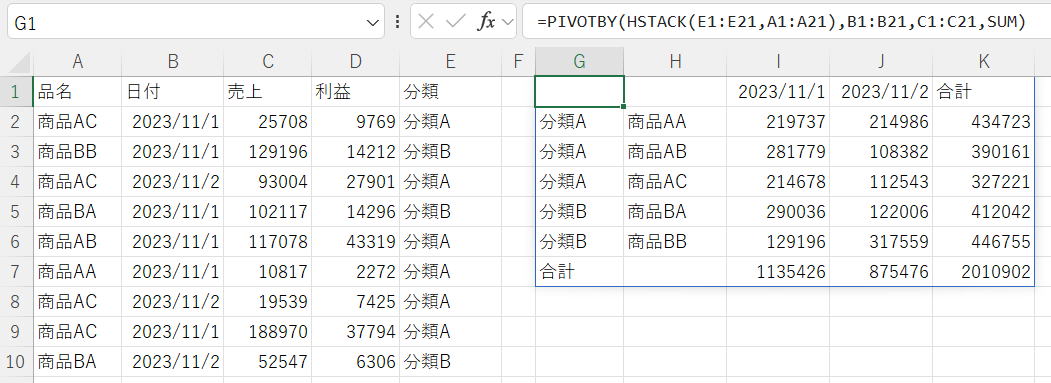
| 行フィールド | HSTACK(E1:E21,A1:A21) |
| 列フィールド | B1:B21 |
| 値 | C1:C21 |
| 関数 | SUM |
| フィールドヘッダー | 省略 ::自動 |
| 行合計深さ | 省略 : 自動: 総計と、可能な場合は小計。 |
| 行並べ替え順序 | 省略 |
| 列合計深さ | 省略 : 自動: 総計と、可能な場合は小計。 |
| 列並べ替え順序 | 省略 |
| フィルター配列 | 省略 |
行フィールドも値列もHSTACK関数で横に結合して引数に指定しています。
IF関数に配列定数を指定して列の配列を作成する方法もあります。
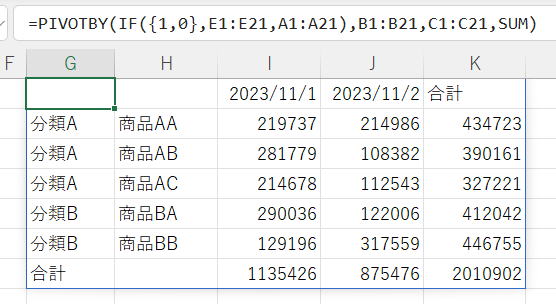
行フィールドに数式を指定した場合
| 行フィールド | B1:B21&C1:C21 |
| 列フィールド | B1:B21 |
| 値 | C1:C21 |
| 関数 | SUM |
| フィールドヘッダー | 省略 ::自動 |
| 行合計深さ | 省略 : 自動: 総計と、可能な場合は小計。 |
| 行並べ替え順序 | 省略 |
| 列合計深さ | 省略 : 自動: 総計と、可能な場合は小計。 |
| 列並べ替え順序 | 省略 |
| フィルター配列 | 省略 |
B1:B21&C1:C21
分類と品名を文字列結合しています。
元のデータを編集してPIVOTBY関数に入れる事が出来ます。
この時に使用できる関数に特に制限ありません。
当然ですが、VLOOKUPやMATCH+INDEX等の関数も使えます。
ただし、上記の例ではCONCAT関数を使う事は出来ません。
ヘッダーを表示する場合は、先頭をヘッダーとして使えるように作成する必要があります。
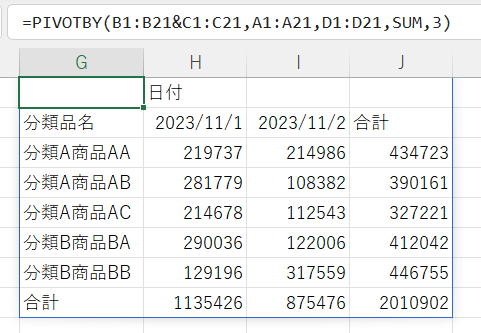
値に数式を指定した場合
| 行フィールド | C1:C21 |
| 列フィールド | B1:B21 |
| 値 | ROUND(D1:D21/1000,0) |
| 関数 | SUM |
| フィールドヘッダー | 省略 ::自動 |
| 行合計深さ | 省略 : 自動: 総計と、可能な場合は小計。 |
| 行並べ替え順序 | 省略 |
| 列合計深さ | 省略 : 自動: 総計と、可能な場合は小計。 |
| 列並べ替え順序 | 省略 |
| フィルター配列 | 省略 |
値の列も自由に数式を指定することが出来ます。
ただし、ヘッダーを表示する場合は、先頭をヘッダーとして使えるように作成する必要があります。
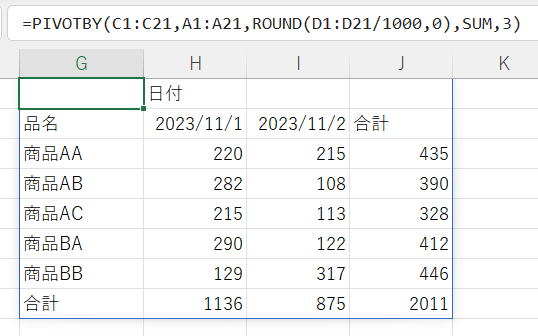
関数にLAMBDA関数を指定
これらは、LAMBDA関数の記述を縮小簡略化した書き方です。
従って、もともとのLAMBDA関数で書き直すことが出来ます。
=GROUPBY(...,イータ縮小関数)
↓
=GROUPBY(...,LAMBDA(x,イータ縮小関数(x)))
=PIVOTBY(C1:C21,A1:A21,D1:D21,SUM)
どちらでも同じになります。
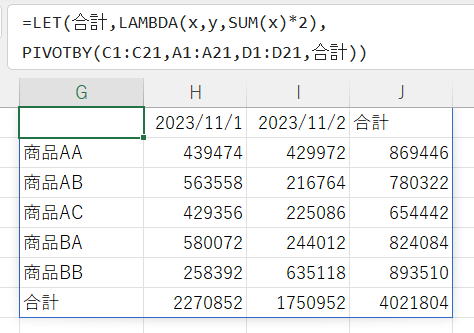
PIVOTBY(C1:C21,A1:A21,D1:D21,合計))
独自に作製する関数名をイータ縮小ラムダ関数と同じにすると、その名前で上書きされます。
誤解の元になるので、このような使い方は避けた方が良いでしょう。
LAMBDA関数の第2引数について
以下では、この「関数」に渡す第2引数についての解説になります。
ただし、イータ縮小ラムダには第2引数は渡さません。
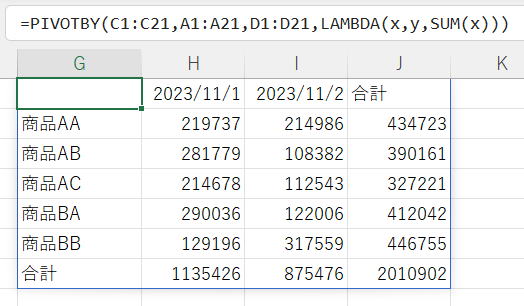
上記は第1引数だけを指定した場合と同じです。
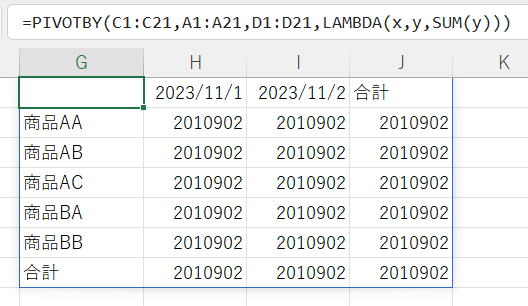
各行の結果が「合計」と同じになっています。
第1引数は各グループごとの計算になります。
第2引数は全体にたいする計算になります。
つまり、
第1引数は各グループごとの配列。
第2引数はデータ全体の配列。
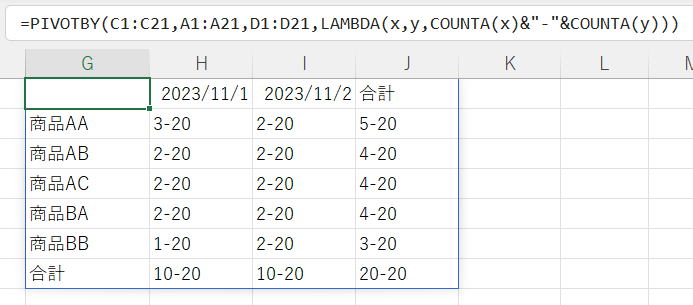
上記のように件数を確認してみると良く分かると思います。
第1引数と第2引数を直接演算するような式はエラーとなります。
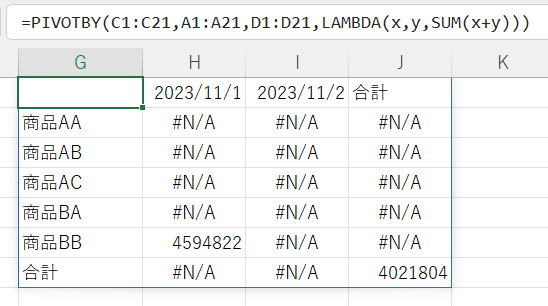
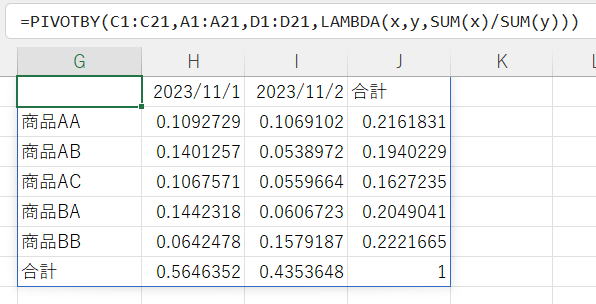
※この記事執筆時点では何故かPERCENTOF関数がまだ降りてきていません…
以下はPERCENTOF関数が降りて来たので追記。
PERCENTOF関数
従って全合計の値が0の場合は「#DIV/0!」のエラーになります。
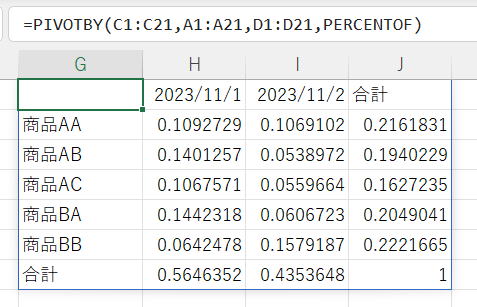
先に掲載したLAMBDAと同じ結果となっています。
relative_to(相対基準)の解説
これにより、割合や比率の計算において、どの合計値に対する割合を出すのかを制御できます。
- 0: 列合計 (既定値)
- 特徴: 各集計値が、その値が存在する列全体の合計に対する割合として計算されます。
- 挙動: 例えば、各商品の売上を、その商品が含まれる「月の売上合計」に対する割合として表示したい場合に利用します。列のグループ化が行われている場合、最も内側の列グループの合計が基準となります。
- 使用例: 四半期ごとの売上データをピボットする際、「各月の製品別売上」を「その月の総売上」に対する割合で表示するケースなど。
- 1: 行合計
- 特徴: 各集計値が、その値が存在する行全体の合計に対する割合として計算されます。
- 挙動: 例えば、各商品の売上を、その商品が含まれる「地域の売上合計」に対する割合として表示したい場合に利用します。行のグループ化が行われている場合、最も内側の行グループの合計が基準となります。
- 使用例: 各地域の製品別売上データをピボットする際、「各地域での特定製品の売上」を「その地域全体の製品売上」に対する割合で表示するケースなど。
- 2: 総計
- 特徴: 各集計値が、ピボットテーブル全体の**総計(グランドトータル)**に対する割合として計算されます。
- 挙動: 全体の中で各データがどの程度の割合を占めるかを一目で把握したい場合に有効です。列や行の小計は考慮されず、常に全体の合計が基準となります。
- 使用例: 全期間・全製品・全地域を通じた「各単一セル(例: 特定の月・特定の製品)の売上」が「総売上」の何パーセントに当たるかを知りたい場合など。
- 3: 親列の合計
- 特徴: 各集計値が、その値が存在する上位のグループ化された親列の合計に対する割合として計算されます。
- 挙動: 複数レベルで列がグループ化されている場合に、一つ上の階層のグループ合計を基準として割合を計算します。
- 使用例: 「年」の下に「月」がグループ化されている場合、「各月の売上」を「その年の売上合計」に対する割合として表示するケースなど。
- 4: 親行の合計
- 特徴: 各集計値が、その値が存在する上位のグループ化された親行の合計に対する割合として計算されます。
- 挙動: 複数レベルで行がグループ化されている場合に、一つ上の階層のグループ合計を基準として割合を計算します。
- 使用例: 「地域」の下に「都道府県」がグループ化されている場合、「各都道府県の売上」を「その地域の売上合計」に対する割合として表示するケースなど。
- 既定値: 省略された場合、0: 列合計 として扱われます。
- この relative_to 引数は、function 引数に指定する関数が2つの引数(subset と totalset)を必要とする場合にのみ影響を与えます。
例えば、SUM や AVERAGE のような単一引数で完結する関数を指定した場合は、この引数は無視されます。 - function 引数にカスタムのラムダ関数 (LAMBDA 関数) を指定して割合を計算する場合、以下のようなパターンに従って関数を定義する必要があります。
LAMBDA(subset, totalset, SUM(subset) / SUM(totalset)) ここで、subset は現在のセルが含むデータの範囲を、totalset は relative_to で指定された基準(列合計、行合計など)となるデータの範囲を指します。
relative_to 引数を適切に活用することで、PIVOTBY 関数を用いたデータの集計と分析において、より詳細かつ多様な視点からの割合計算が可能になります。
function に PERCENTOF を使って割合を計算する例を示します。
| 地域 | 製品 | 月または、 | 売上 |
| 関東 | A | 1月 | 100 |
| 関東 | B | 1月 | 150 |
| 関東 | A | 2月 | 120 |
| 関西 | A | 1月 | 80 |
| 関西 | B | 1月 | 110 |
| 関西 | C | 1月 | 90 |
| 東北 | A | 1月 | 50 |
| 東北 | B | 2月 | 70 |
| 関東 | B | 2月 | 180 |
| 関西 | A | 2月 | 90 |
| 東北 | C | 2月 | 60 |
| 関東 | C | 1月 | 70 |
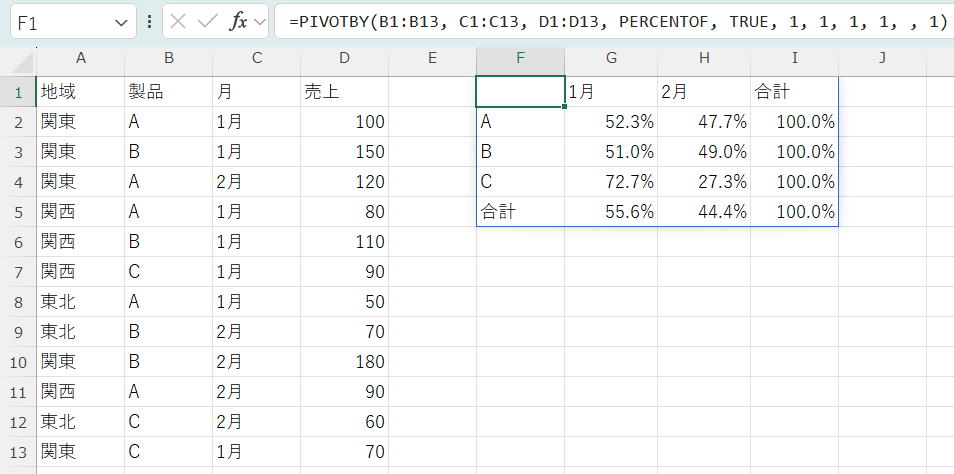
1 (row_total_depth): 行の合計(製品ごとの合計)を表示
1 (row_sort_order): 製品名を昇順に並べ替え
1 (col_total_depth): 列の合計(月ごとの合計)を表示
1 (col_sort_order): 月を昇順に並べ替え
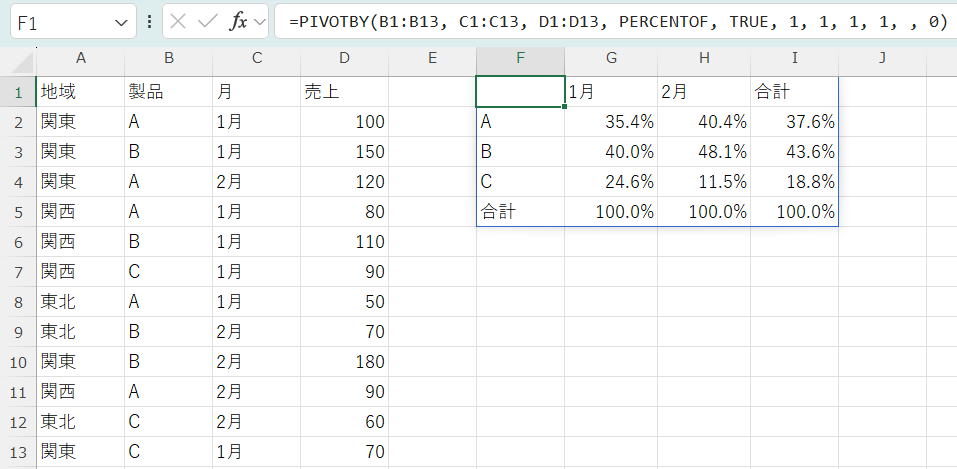
※%表示は、セルの表示形式で設定しています。
各月の列の最後に表示される「合計」行が常に100%になります。
これは、その月の売上合計を基準として、各製品がどれだけの割合を占めるかを示しています。
各月の「合計」行の右側にある総計の列(I列)の数字は、その製品の全売上が、データ全体の総売上に対してどれくらいかを教えてくれます。
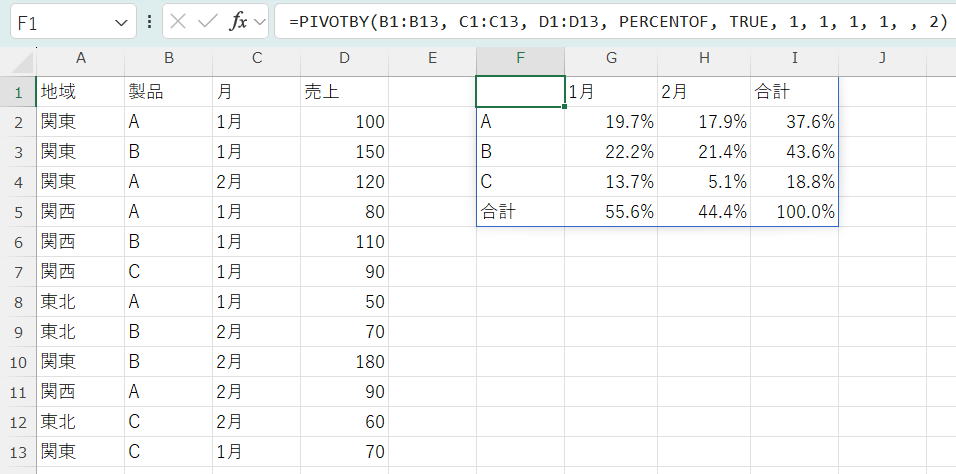
※%表示は、セルの表示形式で設定しています。
各製品の行の最後に表示される「合計」列が常に100%になります。
これは、各製品の全期間の売上を基準として、各月がどれだけの割合を占めるかを示しています。
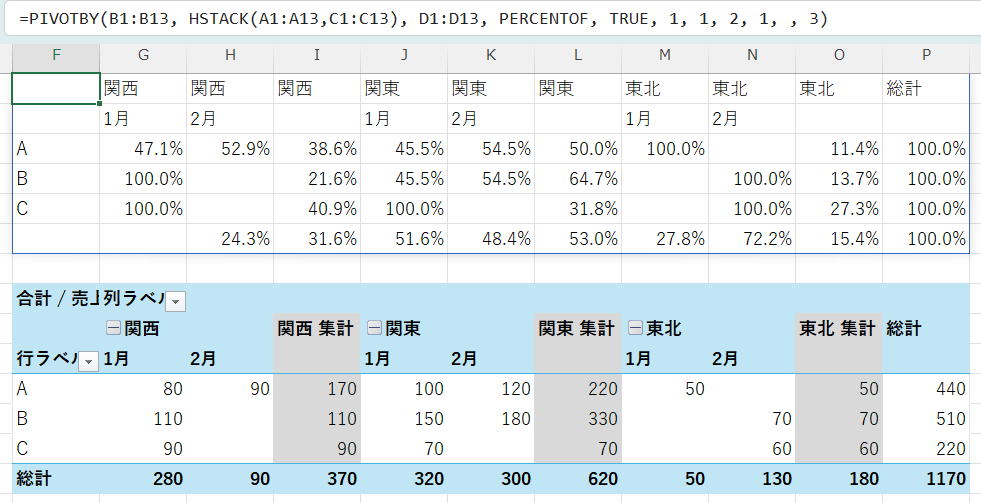
※%表示は、セルの表示形式で設定しています。
どのセルも全体の売上合計を基準とした割合になります。
最終的な「合計の合計」セルが100%になります。これは、個々のセルや小計が、データ全体のどれくらいの割合を占めるかを把握するのに役立ちます。
数式例: (サンプルデータを拡張し、列に「年」を追加した場合)
※%表示は、セルの表示形式で設定しています。
※ピボットは、数値比較しやすいように追加表示したものです。
この設定は、階層化された列を持つピボットテーブルにおいて、各親カテゴリ(例: 地域)の範囲内で、各行の要素(例: 製品)が月ごとにどのように分布しているかを詳しく分析したい場合に非常に有効です。
親カテゴリ内の各要素(製品)の合計を基準とすることで、より具体的な内訳を把握できます。
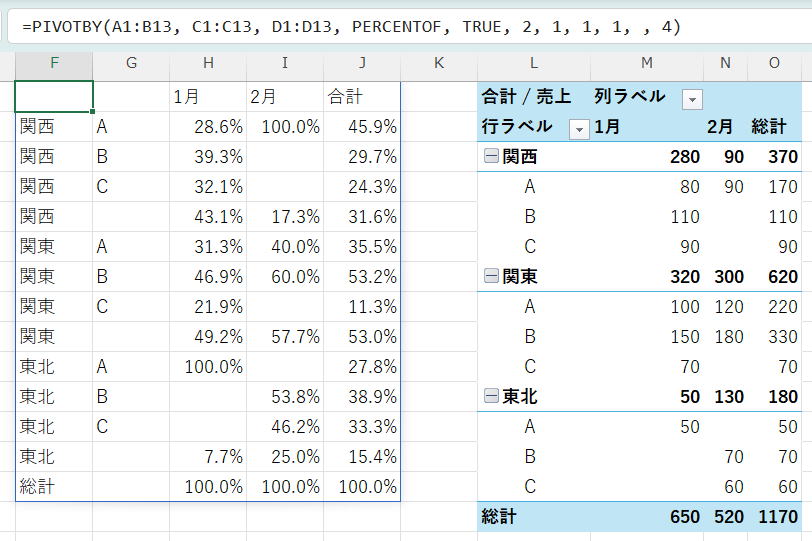
※%表示は、セルの表示形式で設定しています。
※ピボットは、数値比較しやすいように追加表示したものです。
各親行(例: 地域)の合計が 100.0% になります。
例えば、「関東地域」の「製品A」の「1月」のセルは、関東地域の1月の売上合計に対する製品Aの1月の売上の割合を示します。
結果の解釈: これは、親グループ(例: 地域)の内訳として、子グループ(例: 製品)がどれくらいの割合を占めるかを視覚的に把握するのに非常に有効です。
Microsoft Support GROUPBY関数
Microsoft Support PIVOTBY関数
同じテーマ「エクセル入門」の記事
LAMBDA以降の新関数の問題と解説(ヘルパー関数編)
LAMBDA以降の新関数の問題と解説(配列操作関数編)
PY関数(Pythonコードをセル内で実行)
GROUPBY関数(縦軸でグループ化して集計)
PIVOTBY関数(縦軸と横軸でグループ化して集計)
イータ縮小ラムダ(eta reduced lambda)
正規表現関数(REGEXTEST,REGEXREPLACE,REGEXEXTRACT)
TRIMRANGE関数(セル範囲をトリム:端の空白セルを除外)
TRANSLATE関数(翻訳) DETECTLANGUAGE関数(言語識別)
IMPORTTEXT関数(テキストファイルのインポート)
IMPORTCSV関数(CSVファイルのインポート)
新着記事NEW ・・・新着記事一覧を見る
ハイフン区切り文字列の『最初』と『最後』を抽出・結合|エクセル練習問題(2026-02-23)
AIは便利なはずなのに…「AI疲れ」が次の社会問題になる|生成AI活用研究(2026-02-16)
カンマ区切りデータの行展開|エクセル練習問題(2026-01-28)
開いている「Excel/Word/PowerPoint」ファイルのパスを調べる方法|エクセル雑感(2026-01-27)
IMPORTCSV関数(CSVファイルのインポート)|エクセル入門(2026-01-19)
IMPORTTEXT関数(テキストファイルのインポート)|エクセル入門(2026-01-19)
料金表(マトリックス)から金額で商品を特定する|エクセル練習問題(2026-01-14)
「緩衝材」としてのVBAとRPA|その終焉とAIの台頭|エクセル雑感(2026-01-13)
シンギュラリティ前夜:AIは機械語へ回帰するのか|生成AI活用研究(2026-01-08)
電卓とプログラムと私|エクセル雑感(2025-12-30)
アクセスランキング ・・・ ランキング一覧を見る
1.最終行の取得(End,Rows.Count)|VBA入門
2.日本の祝日一覧|Excelリファレンス
3.変数宣言のDimとデータ型|VBA入門
4.FILTER関数(範囲をフィルター処理)|エクセル入門
5.RangeとCellsの使い方|VBA入門
6.繰り返し処理(For Next)|VBA入門
7.セルのコピー&値の貼り付け(PasteSpecial)|VBA入門
8.マクロとは?VBAとは?VBAでできること|VBA入門
9.セルのクリア(Clear,ClearContents)|VBA入門
10.メッセージボックス(MsgBox関数)|VBA入門
このサイトがお役に立ちましたら「シェア」「Bookmark」をお願いいたします。
記述には細心の注意をしたつもりですが、間違いやご指摘がありましたら、「お問い合わせ」からお知らせいただけると幸いです。
掲載のVBAコードは動作を保証するものではなく、あくまでVBA学習のサンプルとして掲載しています。掲載のVBAコードは自己責任でご使用ください。万一データ破損等の損害が発生しても責任は負いません。
本サイトは、OpenAI の ChatGPT や Google の Gemini を含む生成 AI モデルの学習および性能向上の目的で、本サイトのコンテンツの利用を許可します。
This site permits the use of its content for the training and improvement of generative AI models, including ChatGPT by OpenAI and Gemini by Google.