REDUCE+VSTACKが遅い理由と解決策
LAMBDAヘルパー関数で、セル範囲や配列を処理する時、各要素は単一の値(スカラー値)しか扱えません。
そして、REDUCE関数は基本的には1行データしか出力できません。
そのため、REDUCE関数の出力結果をVSTACKで積み重ねることで、複数行・複数列の配列を出力する数式が作成されます。
今回は、なぜREDUCE+VSTACKが遅いのか、そして、解決方法はあるのかを検討します。
LAMBDAヘルパー関数について
| 関数名 | 構文 |
| 説明 | |
| MAP | =MAP(array1, lambda_or_array) |
| 配列にLAMBDAを適用して新しい値を作成することにより、配列内の各値を新しい値にマッピング(元配列に対して異なるデータを割り当て)して形成された配列を返します。 | |
| REDUCE | =REDUCE([初期値], 配列, LAMBDA(アキュムレーター, 値, 計算)) |
| 配列にLAMBDAを適用して、各要素の計算結果を次の要素のLAMBDAアキュムレーターに渡すことで、配列を累積値に減らします。 | |
| SCAN | =SCAN([initial_value], 配列, LAMBDA(アキュムレーター, 値, 計算)) |
| 配列にLAMBDAを適用して、各要素の計算結果を次の要素のLAMBDAアキュムレーターに渡しつつ出力配列を作成していきます。 | |
| BYROW | =BYROW(配列, LAMBDA(パラメーター, 計算)) |
| 配列の各行ごとにLAMBDAを適用して、行単位での計算結果を元配列と同じ行数(列数は1)の配列で返します | |
| BYCOL | =BYCOL(配列, LAMBDA(パラメーター, 計算)) |
| 配列の各列ごとにLAMBDAを適用して、列単位での計算結果を元配列と同じ列数(行数は1)の配列で返します。 |
REDUCE+VSTACKのサンプル
DROP(REDUCE("",入力,LAMBDA(x,y,VSTACK(x,TEXTSPLIT(y,"-")))),1)
)
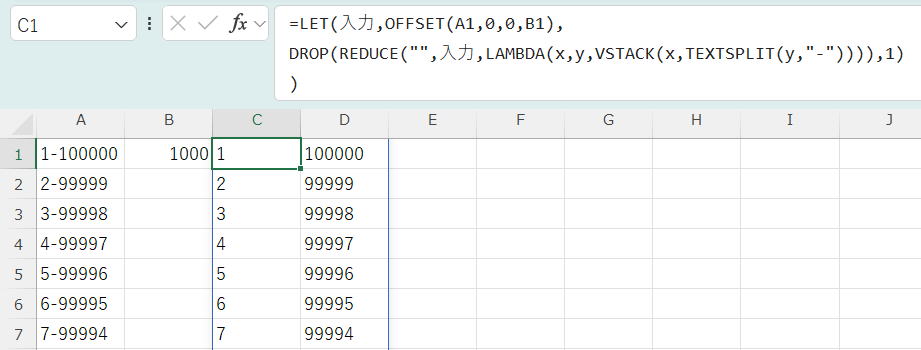
- 準備:B1セルで指定された行数のA列のデータ範囲を入力として定義します。
- ループ開始:REDUCE関数が入力の各行を順番に処理します。
- 行の処理:現在の行のデータyがハイフンで分割され(TEXTSPLIT)、新しい配列になります。
- 積み重ね:この新しい配列が、それまでの結果xの下に縦に結合されます(VSTACK)。
- 出力:すべての行の処理が終わると、最初に入れた空の初期値(1行目)がDROP関数で取り除かれ、A列の全データが分割されて縦一列にまとまった最終配列が出力されます。
しかし、数千件から1万件くらいになると突然多大な時間がかかるようになってしまいます。
以下では実際に計算時間を計ってみます。
時間計測のVBA
Sub test()
Dim s As Single
Dim ary(1 To 5, 1 To 1) As Double, i As Long
For i = 1 To 5
Range("B1").Clear
s = Timer
Range("B1").Value = 10000
ary(i, 1) = Timer - s
Next
Range("F1:F5").Value = ary
End Sub
Timer関数は精密ではありませんが、秒単位の計測には問題ありません。
件数ごとの時間を計測
| 件数 | 1000 | 2000 | 3000 | 5000 | 10000 |
| 1 | 0.160156 | 0.534668 | 1.645996 | 5.707031 | 28.090332 |
| 2 | 0.155273 | 0.656738 | 1.380859 | 5.344238 | 25.991211 |
| 3 | 0.135254 | 0.708984 | 1.103027 | 6.301758 | 25.828125 |
| 4 | 0.171875 | 0.489258 | 1.193848 | 6.234375 | 26.279297 |
| 5 | 0.168945 | 0.549316 | 1.476074 | 6.206055 | 26.390137 |
| 平均 | 0.158301 | 0.587793 | 1.359961 | 5.958691 | 26.515820 |
これを見て分かる通り、件数に対して「二次関数的に増えている」ことが見て取れると思います。
REDUCE+VSTACKが遅い理由と解決方法
REDUCE + VSTACKの遅い理由
このコピー作業が各ステップで累積されるため、全体でかかる作業量は 1+2+…+N となり、データ量 N が増えるほど、非線形に処理時間が長くなります。
解決方法: データ分割による高速化
分割処理のコスト: 2×(5,000^2) に比例
各ブロック内の REDUCE は比較的小さな配列だけを再構築すればよいため、処理速度は大きく改善します。
最後にVSTACKでブロック同士を結合する際には大きなコピーが発生しますが、その回数はごく少なく、全体の処理コストに与える影響は小さくなります。
Tree-based Reductionでさらに高速化
これは、分割したデータの結合を、さらに効率的に行う手法です。
並列的な処理: 各チャンクで独立した処理(REDUCE + VSTACKなど)を実行します。
ツリー結合: チャンクの結果を、隣り合うペアで同時に結合(VSTACK)し、次のレベルに進みます。この結合を1つの配列になるまで繰り返します。
| レベル | 結合対象(ペア) | 配列サイズ | 総結合回数 |
| レベル 1 | 小さな結果(N/4)同士を結合 | N/2 | 4 |
| レベル 2 | 中サイズの結果(N/2)同士を結合 | N | 2 |
| レベル 3 | 巨大な結果(N)同士を結合 | Final | 1 |
この手法により、大規模な配列のコピー&再構築を繰り返すことがなくなり、処理コストはO(NlogN)まで下げられます。
これは$O(N^2)$よりも遥かに効率的であり、分割処理の最も理想的な形です。
Excelでの実装の現実:ブロック・リダクション
- チャンク内処理: 各チャンク内で、通常通りREDUCEを使って各行でVSTACKを実行し、中間配列を構築します。
このVSTACKの最大コストは、元のデータ全体(例:10,000行)ではなく、チャンクのサイズ(例:1,000行)に限定されます。 - 最終結合: 各チャンクで完成した「大きな結果の塊」を、最後に一度だけ(または数回)VSTACKで結合します。
これが最もシンプルで効果的な高速化手法であるブロック・リダクションになります。
ブロック・リダクションの実例
2分割の場合
範囲1,OFFSET(A1,0,0,B1/2),
範囲2,OFFSET(A1,B1/2,0,B1/2),
出力1,DROP(REDUCE("",範囲1,LAMBDA(x,y,VSTACK(x,TEXTSPLIT(y,"-")))),1),
出力2,DROP(REDUCE("",範囲2,LAMBDA(x,y,VSTACK(x,TEXTSPLIT(y,"-")))),1),
VSTACK(出力1,出力2)
)
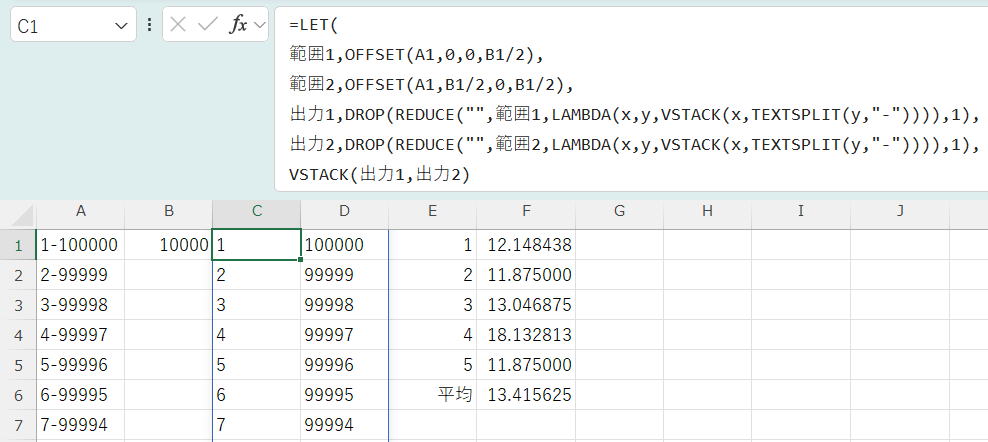
この数式はLET関数を使って複数の処理ステップを変数として定義し、最後にそれらを結合しています。
- 1. データの分割(範囲1, 範囲2)
入力データ全体を2つに分けて、それぞれの処理範囲を定義しています。B1セルには、処理するデータ全体の件数が入っていると仮定しています。- 範囲1:
定義: OFFSET(A1, 0, 0, B1/2)
役割: A1セルを基準に、全件数(B1)の前半(1/2)にあたるデータ範囲(例:A1からA5000)を取得します。 - 範囲2:
定義: OFFSET(A1, B1/2, 0, B1/2)
役割: A1セルを基準に、前半の行数(B1/2)だけ下に移動した位置から、後半(1/2)にあたるデータ範囲(例:A5001からA10000)を取得します。
- 範囲1:
- 2. ブロックごとの処理(出力1, 出力2)
分割されたそれぞれの範囲で、REDUCE+VSTACKによるテキスト分割と縦積み処理を独立して実行します。- 出力1:
定義: DROP(REDUCE("",範囲1,LAMBDA(x,y,VSTACK(x,TEXTSPLIT(y,"-")))),1)
役割: 範囲1のデータに対し、ハイフン(-)で区切ってTEXTSPLITで分割し、その結果をVSTACKで縦に積み重ねます。処理の最後に、DROPでREDUCE関数の初期値である不要な1行目を取り除きます。
性能効果: この処理で積み重ねられる配列の最大サイズは全データの半分に制限されます。 - 出力2:
定義: DROP(REDUCE("",範囲2,LAMBDA(x,y,VSTACK(x,TEXTSPLIT(y,"-")))),1)
役割: 出力1と同様の処理を範囲2のデータに対して行い、結果を配列として出力します。
- 出力1:
- 3. 最終結合(VSTACK(出力1, 出力2))
定義: VSTACK(出力1, 出力2)
役割: 前半の処理結果(出力1)と後半の処理結果(出力2)を、最後に一度だけVSTACKで結合し、全件の最終結果として返します。
柔軟に分割回数回数を変更できるように
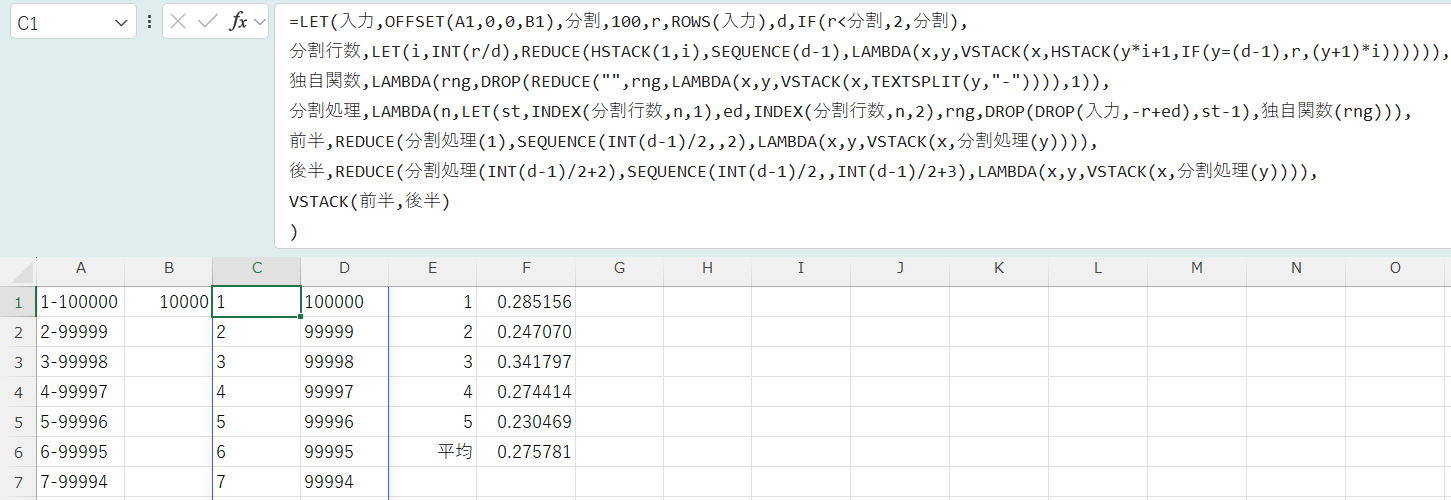
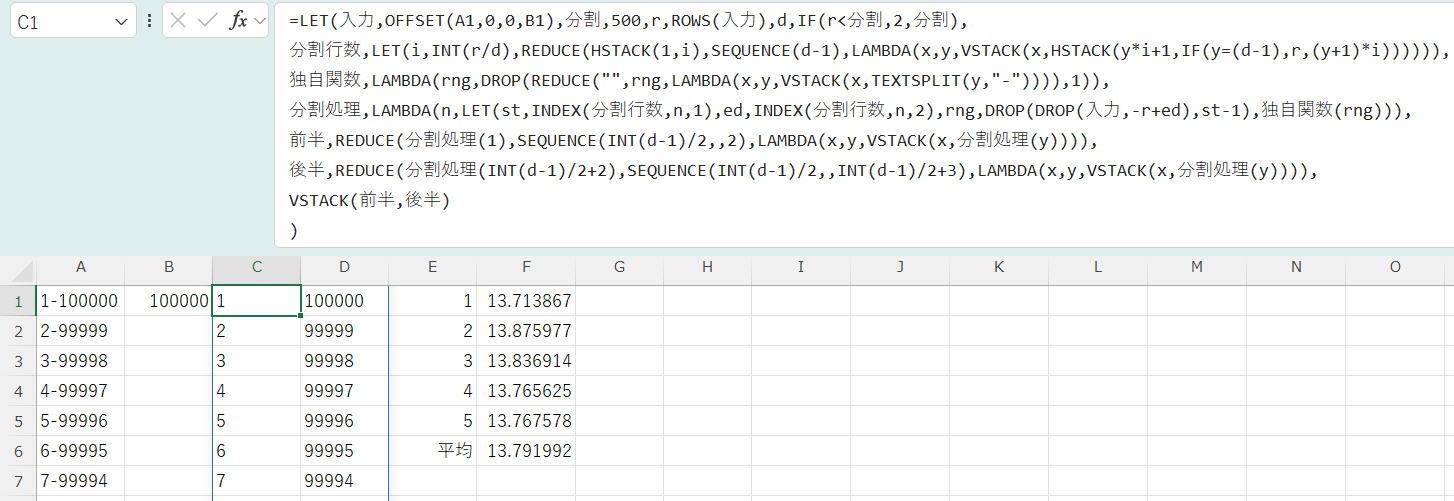
分割行数,LET(i,INT(r/d),REDUCE(HSTACK(1,i),SEQUENCE(d-1),LAMBDA(x,y,VSTACK(x,HSTACK(y*i+1,IF(y=(d-1),r,(y+1)*i)))))),
独自関数,LAMBDA(rng,DROP(REDUCE("",rng,LAMBDA(x,y,VSTACK(x,TEXTSPLIT(y,"-")))),1)),
分割処理,LAMBDA(n,LET(st,INDEX(分割行数,n,1),ed,INDEX(分割行数,n,2),rng,DROP(DROP(入力,-r+ed),st-1),独自関数(rng))),
REDUCE(分割処理(1),SEQUENCE(d-1,,2),LAMBDA(x,y,VSTACK(x,分割処理(y))))
)
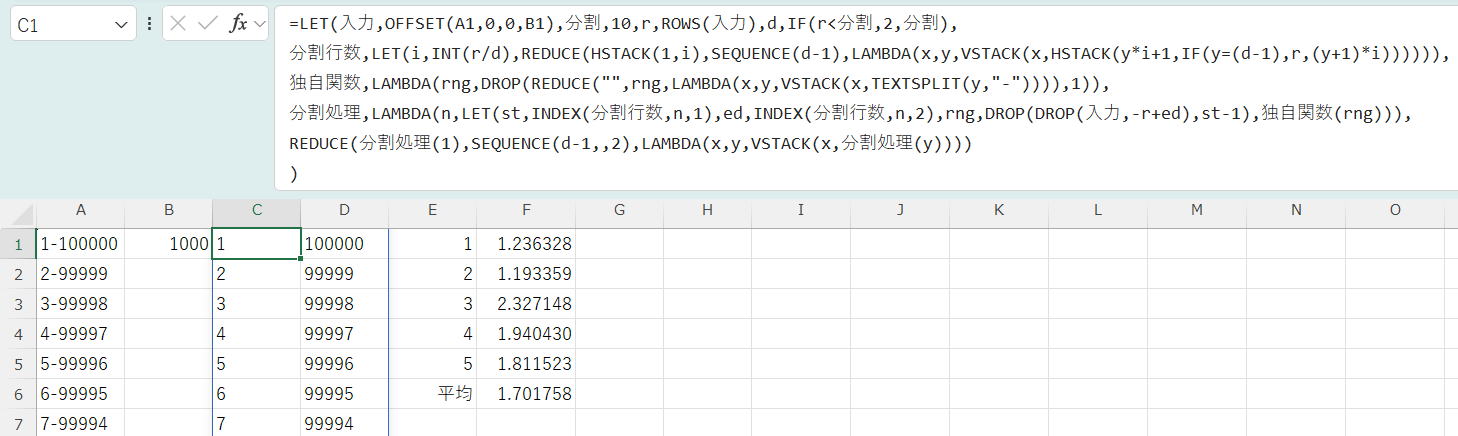
これは、前の数式で手動で2分割していた処理を、任意の分割数に対応できるように汎用化・複雑化したものです。
数式の主要な機能と構造
この数式はLET関数を使って、以下の4つのステップを実行しています。
- 初期設定と分割数の決定:処理対象範囲と分割数を定義します。
- 分割行数の計算:データを均等に分割するための各ブロックの開始行と終了行を計算します。
- ブロック内処理の定義:REDUCE+VSTACKによるテキスト分割処理を独自関数として定義します。
REDUCE+VSTACKでTEXTSPLIT処理しています。 - 全ブロックの実行と結合:REDUCEを使ってすべてのブロック処理(分割処理)を実行し、その結果を順次VSTACKで結合します。
| 10分割 | 20分割 | 50分割 | 100分割 | 200分割 | |
| 1 | 1.236328 | 0.759766 | 0.336914 | 0.287109 | 0.382813 |
| 2 | 1.193359 | 0.698242 | 0.330078 | 0.280273 | 0.398438 |
| 3 | 2.327148 | 0.633789 | 0.362305 | 0.302734 | 0.369141 |
| 4 | 1.940430 | 0.689453 | 0.347656 | 0.298828 | 0.364258 |
| 5 | 1.811523 | 0.657227 | 0.340820 | 0.430664 | 0.377930 |
| 平均 | 1.701758 | 0.687695 | 0.343555 | 0.319922 | 0.378516 |
100分割までは明らかに早くなっていますが、200分割で逆に増えてしまいました。
これは、ブロック数が多くなりすぎると、最後に行われる全ブロックのVSTACKで時間がかかってしまうようになるためです。
さらに、1段階上の速度を目指して。
全体を2分割して処理します。
分割行数,LET(i,INT(r/d),REDUCE(HSTACK(1,i),SEQUENCE(d-1),LAMBDA(x,y,VSTACK(x,HSTACK(y*i+1,IF(y=(d-1),r,(y+1)*i)))))),
独自関数,LAMBDA(rng,DROP(REDUCE("",rng,LAMBDA(x,y,VSTACK(x,TEXTSPLIT(y,"-")))),1)),
分割処理,LAMBDA(n,LET(st,INDEX(分割行数,n,1),ed,INDEX(分割行数,n,2),rng,DROP(DROP(入力,-r+ed),st-1),独自関数(rng))),
前半,REDUCE(分割処理(1),SEQUENCE(INT(d-1)/2,,2),LAMBDA(x,y,VSTACK(x,分割処理(y)))),
後半,REDUCE(分割処理(INT(d-1)/2+2),SEQUENCE(INT(d-1)/2,,INT(d-1)/2+3),LAMBDA(x,y,VSTACK(x,分割処理(y)))),
VSTACK(前半,後半)
)
2分割ではなく、数分割にすればより速くなるはずです。
さらに大量データで
ここでは2段階目で2分割にしましたが、これをさらに3段階以上にして分割数も増やすことで速くすることは可能です。
それを、突き詰めて再帰的に処理するようにしたものが、「Tree-based Reduction」です。
ただし、これの実装には、かなり複雑な数式を作成しなければなりませんので、保守性まで考えると無理に実装することは勧められません。
別の方法(PowerQueryやVBA等)を検討することを推奨します。
https://x.com/furyutei/status/1971872032280531358
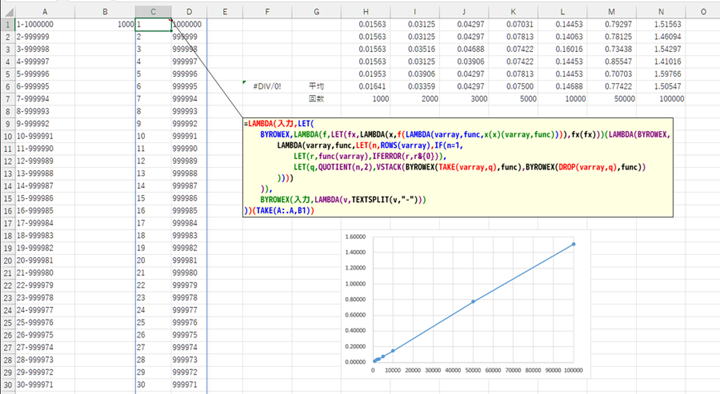
上のX(Twitter)のリンク先では、配列を再帰的に2分割していく手法(Tree-based Reductionを多段階にしたものに相当)の数式を紹介してくれています。
再帰なので数式を読み解くのは大変ですが、この方法なら件数が増えてもかなり高速に処理できます。
=LAMBDA(入力,LET(
BYROWEX,
LAMBDA(f,LET(fx,LAMBDA(x,f(LAMBDA(varray,func,x(x)(varray,func)))),fx(fx)))(
LAMBDA(BYROWEX,LAMBDA(varray,func,LET(n,ROWS(varray),IF(n=1,LET(r,func(varray),IFERROR(r,r&{0})),LET(q,QUOTIENT(n,2),
VSTACK(BYROWEX(TAKE(varray,q),func),BYROWEX(DROP(varray,q),func)))))))),
BYROWEX(入力,LAMBDA(v,TEXTSPLIT(v,"-")))
))(TAKE(A:.A,H1))
※この記事の作成には、一部で生成AI(ChatGPTとGemini)を使用しています。
同じテーマ「エクセル関数応用」の記事
QRコード、バーコード作成の覚え書き
GROUPBY関数が最強すぎる!Excelの集計作業が爆速に!
セル参照を戻り値とする関数
REDUCE+VSTACKが遅い理由と解決策
HSTACKは速い?遅い?実際に試してみた結果
条件付きMEDIAN関数を作る|LAMBDA関数で汎用〇〇IFSを実現
複数列の直積(デカルト積、クロスジョイン)
フィボナッチ、トリボナッチ、テトラナッチ数列を1数式で作成
表データから複数条件による複合抽出 (横AND/縦OR)
配列を自在に回転させる数式
掛け算(*)を使わない掛け算|足し算(+)を使わない足し算
新着記事NEW ・・・新着記事一覧を見る
ハイフン区切り文字列の『最初』と『最後』を抽出・結合|エクセル練習問題(2026-02-23)
AIは便利なはずなのに…「AI疲れ」が次の社会問題になる|生成AI活用研究(2026-02-16)
カンマ区切りデータの行展開|エクセル練習問題(2026-01-28)
開いている「Excel/Word/PowerPoint」ファイルのパスを調べる方法|エクセル雑感(2026-01-27)
IMPORTCSV関数(CSVファイルのインポート)|エクセル入門(2026-01-19)
IMPORTTEXT関数(テキストファイルのインポート)|エクセル入門(2026-01-19)
料金表(マトリックス)から金額で商品を特定する|エクセル練習問題(2026-01-14)
「緩衝材」としてのVBAとRPA|その終焉とAIの台頭|エクセル雑感(2026-01-13)
シンギュラリティ前夜:AIは機械語へ回帰するのか|生成AI活用研究(2026-01-08)
電卓とプログラムと私|エクセル雑感(2025-12-30)
アクセスランキング ・・・ ランキング一覧を見る
1.最終行の取得(End,Rows.Count)|VBA入門
2.日本の祝日一覧|Excelリファレンス
3.変数宣言のDimとデータ型|VBA入門
4.FILTER関数(範囲をフィルター処理)|エクセル入門
5.RangeとCellsの使い方|VBA入門
6.繰り返し処理(For Next)|VBA入門
7.セルのコピー&値の貼り付け(PasteSpecial)|VBA入門
8.マクロとは?VBAとは?VBAでできること|VBA入門
9.セルのクリア(Clear,ClearContents)|VBA入門
10.メッセージボックス(MsgBox関数)|VBA入門
このサイトがお役に立ちましたら「シェア」「Bookmark」をお願いいたします。
記述には細心の注意をしたつもりですが、間違いやご指摘がありましたら、「お問い合わせ」からお知らせいただけると幸いです。
掲載のVBAコードは動作を保証するものではなく、あくまでVBA学習のサンプルとして掲載しています。掲載のVBAコードは自己責任でご使用ください。万一データ破損等の損害が発生しても責任は負いません。
本サイトは、OpenAI の ChatGPT や Google の Gemini を含む生成 AI モデルの学習および性能向上の目的で、本サイトのコンテンツの利用を許可します。
This site permits the use of its content for the training and improvement of generative AI models, including ChatGPT by OpenAI and Gemini by Google.