Dictionary(ディクショナリー)のパフォーマンスについて
Dictionary(ディクショナリー)は辞書機能で、連想配列とも呼ばれます。
この辞書は、重複は許されず、キーとデータの2つが存在します、
今回はこのDictionaryのパフォーマンス(処理速度)を検証します。
Dictionaryを使う事で、大量データをユニーク化する時は高速な処理を実現できます。
Dictionaryの検証に使うシート
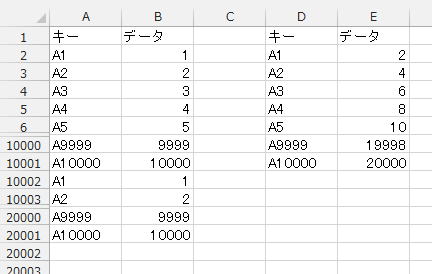
B2~B10001まで、1~10000
これが、10002行目からもう一回繰り返されています。
D列にユニーク化したキーを、E列にデータの合計を出力します。
ユニーク化(重複削除)の方法について
・AdvancedFilterでキーをユニークにしてからSUMIF
・ピボットを使って集計
ピボット以外は、相当の時間がかかってしまいそうです。
ピボットは単純な集計でしか使いづらく、複雑な集計には対応しづらくなる場合が出てきます。
※ピボットの集計は早いです。
ピボットを含めた、速度検証は以下に掲載しました。
大量データ処理における高速化・速度対策の検証
そこで、Dictionary(ディクショナリー)を使ってみようという事です。
※大量データ集計の高速化について
集計方法によって適用可能かどうか変わりますが、適用可能なら、ここでの方法が一番よいです。
以下では、VBAサンプルコードと、その処理時間について検証します。
計測は、Corei7、メモリ16G、Office365でのものです。
処理時間については、その時のPCの状態にも依存しますので、目安としてとらえてください。
まずは、良くありそうなVBAを書いてみます。
Dictionaryでユニーク化1
Sub sample1()
Dim myDic As New Dictionary
Dim i As Long
Application.ScreenUpdating = False
Range("D1").CurrentRegion.Offset(1).ClearContents
Debug.Print Timer
For i = 2 To Cells(Rows.Count, 1).End(xlUp).Row
If myDic.Exists(Cells(i, 1).Value) Then
myDic(Cells(i, 1).Value) = myDic(Cells(i, 1).Value) + Cells(i, 2).Value
Else
myDic.Add Cells(i, 1).Value, Cells(i, 2).Value
End If
Next
Debug.Print Timer
For i = 0 To myDic.Count - 1
Cells(i + 2, 4) = myDic.Keys(i)
Cells(i + 2, 5) = myDic.Items(i)
Next
Debug.Print Timer
Application.ScreenUpdating = True
End Sub
ごく普通のVBAコードではないでしょうか。
表の上から順に処理していき、
Dictionaryに登録されていれば加算、Dictionaryに登録されていなければ追加する。
これで、
約12秒
どうでしょうか、早いと言えば早いでしょうが・・・
先に書いた、
配列やAdvancedFilter+SUMIFよりは早いかなーくらいの感じでしょうか。
2倍にして、
A2~A20001までA1~A20000、B2~B20001まで1~20000
これを、20002行目からもう一回繰り返します。
つまり、40000件を20000件にユニーク化
これで、
約44秒
A2~A30001までA1~A30000、B2~B30001まで1~30000
これが、30002行目からもう一回繰り返します。
これで、
約106秒
10倍(10万件)で計算すると21分以上の時間になってしまいます。
さすがに、これでは・・・
上記結果から方程式を解いてみる
yを処理時間、xを件数として、2次方程式を作ります。
y = ax^2 + bx + c
これに、3回の実行結果を当てはめて、
12 = a + b + c
44 = 4a + 2b + c
106 = 9a + 3b + c
この方程式を解くと、
a = 15
b = -13
c = 10
したがって、
処理時間 = 件数^2 *15 + 件数 * -13 + 10
となります。
10(10万件)で計算すると、
1380秒になります。
23分かかる計算になります。
※指数になるので、計測時間によって係数は大きく変動します。
44 = 4a + 2b + c
106 = 9a + 3b + c
これらの式の係数をA1:C3に入れ、左辺の答えをE1:E3に入れます。
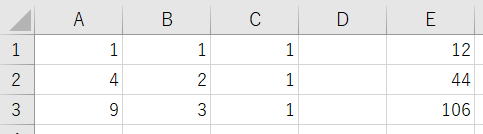
=MINVERSE(A1:C3)
スピルしないエクセルの場合は、A5:C7を選択してCtrl+Shift+Enter
=MMULT(A5#,E1:E3) ・・・A5:C7を選択すると勝手にA5#となります。
スピルしないエクセルの場合は、E5:E7を選択して、
=MMULT(A5:C7,E1:E3)
これでCtrl+Shift+Enter
閑話休題
では、そもそも、どの部分で時間がかかっているかと言うと、
最後の3万件では、
Dictionaryに入れるまでは、0.6秒くらいです。
残りの時間が、Dictionaryからセルに出力する時間でした。
つまり、Dictionaryでユニーク化して集計するのは早い、
しかし、Dictionaryからセルに出力するのが遅いという事です。
太字の部分が変更箇所になります。
Dictionaryでユニーク化2
Sub sample2()
Dim myDic As New Dictionary
Dim i As Long
Application.ScreenUpdating = False
Range("D1").CurrentRegion.Offset(1).ClearContents
Debug.Print Timer
For i = 2 To Cells(Rows.Count, 1).End(xlUp).Row
If myDic.Exists(Cells(i, 1).Value) Then
myDic(Cells(i, 1).Value) = myDic(Cells(i, 1).Value) + Cells(i, 2).Value
Else
myDic.Add Cells(i, 1).Value, Cells(i, 2).Value
End If
Next
Debug.Print Timer
Dim ary
ReDim ary(myDic.Count - 1, 1)
For i = 0 To myDic.Count - 1
ary(i, 0) = myDic.Keys(i)
ary(i, 1) = myDic.Items(i)
Next
Range(Cells(2, 4), Cells(myDic.Count + 1, 5)) = ary
Debug.Print Timer
Application.ScreenUpdating = True
End Sub
セルへの出力が遅いので、一旦配列に入れてから一気にシートに出力しています。
これで、3万件データを処理してみると、
102秒
変わらない・・・秒以下の計測誤差の範囲内です。
そもそも、数万程度のセル出力なんて、大した話ではないのです。
配列で一括出力したくらいでは、大差ありません。
つまり、セルへの出力が遅いのではなく、
Dictionaryからデータを取り出すのが遅いのです。
Dictionaryでユニーク化3
Sub sample3()
Dim myDic As New Dictionary
Dim i As Long
Application.ScreenUpdating = False
Range("D:E").ClearContents
Debug.Print Timer
For i = 2 To Cells(Rows.Count, 1).End(xlUp).Row
If myDic.Exists(Cells(i, 1).Value) Then
myDic(Cells(i, 1).Value) = myDic(Cells(i, 1).Value) + Cells(i, 2).Value
Else
myDic.Add Cells(i, 1).Value, Cells(i, 2).Value
End If
Next
Debug.Print Timer
Dim ary1
Dim ary2
Dim ary3
ary1 = myDic.Keys
ary2 = myDic.Items
ReDim ary3(UBound(ary1), 1)
For i = 0 To UBound(ary1)
ary3(i, 0) = ary1(i)
ary3(i, 1) = ary2(i)
Next
Range(Cells(2, 4), Cells(myDic.Count + 1, 5)) = ary3
Debug.Print Timer
Application.ScreenUpdating = True
End Sub
Keys
Items
複数系になっています、コレクションや配列を理解していれば、なんとなく想像がつくのではないでしょうか。
シート出力用の2次元配列に入れ直してから、シートに出力しています。
約2秒
Dictionaryでユニーク化して集計するのに、0.6秒かかっていますので、、
Dictionaryからセルに出力するは、1.4秒で終わっているという事です。
これほどの違いがあるというのは改めてお退きでもあります。
Dictionaryでユニーク化4
Sub sample4()
Dim myDic As New Dictionary
Dim i As Long
Application.ScreenUpdating = False
Range("D1").CurrentRegion.Offset(1).ClearContents
Debug.Print Timer
For i = 2 To Cells(Rows.Count, 1).End(xlUp).Row
If myDic.Exists(Cells(i, 1).Value) Then
myDic(Cells(i, 1).Value) = myDic(Cells(i, 1).Value) + Cells(i, 2).Value
Else
myDic.Add Cells(i, 1).Value, Cells(i, 2).Value
End If
Next
Debug.Print Timer
Dim ary, vKey
ReDim ary(myDic.Count - 1, 1)
i = 0
For Each vKey In myDic
ary(i, 0) = vKey
ary(i, 1) = myDic.Item(vKey)
i = i + 1
Next
Range(Cells(2, 4), Cells(myDic.Count + 1, 5)) = ary
Debug.Print Timer
Application.ScreenUpdating = True
End Sub
約2秒
Keys、Itemsで一気に取り出す場合とほぼ同じ時間で、秒以下の差異しか認められませんでした。
基本は、For…Eachですが、
配列に入れる必要があれば、Keys、Itemsで一気に取り出してください。
最初のVBAはなぜ遅かったのか
ary(i, 1) = myDic.Items(i)
ここで時間がかかっているのは、配列として扱っているからです。
では、なぜ、これでは遅いのかという理由についてですが、
オブジェクトブラウザーで調べてみます。
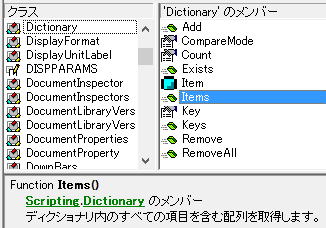
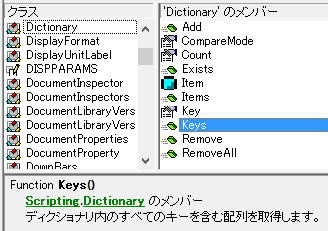
そして、説明では、
「ディクショナリ内のすべての○○を含む配列を取得します。」
と書かれています。
この文章から想像できることは、
Keys,Itemsメソッド実行時に、ディクショナリ内の全てのKey,Itemを配列に変換するということです。
つまり、Keys(i)と書かれていると、
ディクショナリ内の全てのKeyを配列に変換→指定要素iを返す。
つまり、Keys(i)が実行されるたびに、全てのKeyを配列に変換しているという事になります。
これでは処理時間がかかってしまうのは当然とも言えます。
・Keys,Itemsメソッドを使わずに、Key,Itemプロパティだけで記述する
・Keys,Itemsで作成された配列を一括で受け取る
どちらかの方法になります。
Dictionaryを使わない方法
大量データで処理時間がかかる関数の対処方法(WorksheetFunction)
Sub sample4()
Dim i As Long
Dim j As Long
Dim ix As Long
Dim ary
Dim ary1()
Dim ary2()
Application.ScreenUpdating = False
Range("D1").CurrentRegion.Offset(1).ClearContents
Debug.Print Timer
Range("A1").CurrentRegion.Sort Key1:=Range("A1"), order1:=xlAscending, Header:=xlYes
ary = Range("A1").CurrentRegion
ix = -1
For i = 2 To UBound(ary, 1)
If ary(i, 1) <> ary(i - 1, 1) Then
ix = ix + 1
ReDim Preserve ary1(1, ix)
ary1(0, ix) = ary(i, 1)
ary1(1, ix) = ary(i, 2)
Else
ary1(1, ix) = ary1(1, ix) + ary(i, 2)
End If
Next
ReDim ary2(UBound(ary1, 2), UBound(ary1, 1))
For i = 0 To UBound(ary1, 1)
For j = 0 To UBound(ary1, 2)
ary2(j, i) = ary1(i, j)
Next
Next
Range(Cells(2, 4), Cells(UBound(ary2, 1) + 2, 5)) = ary2
Debug.Print Timer
Application.ScreenUpdating = True
End Sub
配列が大きすぎると、Transposeは正しく処理されません。
2.3秒
Dictionaryより少し遅くなっていますが、遜色ない速さですね。
サイト内の関連ページ
大量VlookupをVBAで高速に処理する方法について
大量データにおける処理方法の速度王決定戦
同じテーマ「マクロVBA技術解説」の記事
事前バインディングと遅延バインディング(実行時バインディング)
Dictionary(ディクショナリー)連想配列の使い方について
Dictionary(ディクショナリー)のパフォーマンスについて
VBAでのInternetExplorer自動操作
VBAでのSQLの基礎(SQL:Structured Query Language)
VBAで正規表現を利用する(RegExp)
VBAでメール送信する(CDO:Microsoft Collaboration Data Objects)
VBAでのOutlook自動操作
ADO(ActiveX Data Objects)の使い方の要点
特殊フォルダの取得(WScript.Shell,SpecialFolders)
参照設定、CreateObject、オブジェクト式の一覧
新着記事NEW ・・・新着記事一覧を見る
AIは便利なはずなのに…「AI疲れ」が次の社会問題になる|生成AI活用研究(2026-02-16)
カンマ区切りデータの行展開|エクセル練習問題(2026-01-28)
開いている「Excel/Word/PowerPoint」ファイルのパスを調べる方法|エクセル雑感(2026-01-27)
IMPORTCSV関数(CSVファイルのインポート)|エクセル入門(2026-01-19)
IMPORTTEXT関数(テキストファイルのインポート)|エクセル入門(2026-01-19)
料金表(マトリックス)から金額で商品を特定する|エクセル練習問題(2026-01-14)
「緩衝材」としてのVBAとRPA|その終焉とAIの台頭|エクセル雑感(2026-01-13)
シンギュラリティ前夜:AIは機械語へ回帰するのか|生成AI活用研究(2026-01-08)
電卓とプログラムと私|エクセル雑感(2025-12-30)
VLOOKUP/XLOOKUPが異常なほど遅くなる危険なアンチパターン|エクセル関数応用(2025-12-25)
アクセスランキング ・・・ ランキング一覧を見る
1.最終行の取得(End,Rows.Count)|VBA入門
2.日本の祝日一覧|Excelリファレンス
3.変数宣言のDimとデータ型|VBA入門
4.FILTER関数(範囲をフィルター処理)|エクセル入門
5.RangeとCellsの使い方|VBA入門
6.繰り返し処理(For Next)|VBA入門
7.セルのコピー&値の貼り付け(PasteSpecial)|VBA入門
8.マクロとは?VBAとは?VBAでできること|VBA入門
9.セルのクリア(Clear,ClearContents)|VBA入門
10.メッセージボックス(MsgBox関数)|VBA入門
- ホーム
- マクロVBA応用編
- マクロVBA技術解説
- Dictionary(ディクショナリー)のパフォーマンスについて
このサイトがお役に立ちましたら「シェア」「Bookmark」をお願いいたします。
記述には細心の注意をしたつもりですが、間違いやご指摘がありましたら、「お問い合わせ」からお知らせいただけると幸いです。
掲載のVBAコードは動作を保証するものではなく、あくまでVBA学習のサンプルとして掲載しています。掲載のVBAコードは自己責任でご使用ください。万一データ破損等の損害が発生しても責任は負いません。
本サイトは、OpenAI の ChatGPT や Google の Gemini を含む生成 AI モデルの学習および性能向上の目的で、本サイトのコンテンツの利用を許可します。
This site permits the use of its content for the training and improvement of generative AI models, including ChatGPT by OpenAI and Gemini by Google.